Segment Anything Model (SAM)
Meta AI Research의 혁신적인 세그멘테이션 모델
Notion : https://gugaluv.notion.site/SAM-1e31fcd04676800f863cc6007841d792?pvs=4
목차
- SAM 소개 및 개요
- SAM의 특징
- 모델 구조
- 프롬프트 엔지니어링
- SA-1B 데이터셋
- 활용 사례
- 한계점
- 결론 및 향후 방향
1. SAM 소개 및 개요

Segment Anything Model이란?
- Meta AI Research에서 개발한 프롬프트 기반 이미지 세그멘테이션 모델
- 2023년 4월 발표
- 새로운 태스크: Promptable Segmentation
- 다양한 형태의 프롬프트를 통해 이미지 내 객체 분할 가능
- 강력한 Zero-shot 성능
SAM의 목표
- 범용적인 세그멘테이션 모델 개발
- 다양한 시각적 작업에 적용 가능한 기초 모델 제공
- 사용자 상호작용이 가능한 세그멘테이션 시스템 구축
"모든 것을 분할할 수 있는(Segment Anything)" 모델을 만드는 것
2. SAM의 특징
주요 특징
- 프롬프트 기반: 다양한 프롬프트(점, 박스, 텍스트 등)에 반응
- 실시간 작동: 빠른 응답 속도
- Zero-shot 전이 성능: 학습에 사용되지 않은 데이터셋에서도 우수한 성능
- 유연성: 다양한 세그멘테이션 작업에 적용 가능
- 대규모 데이터셋: SA-1B(11M 이미지, 1.1B 마스크)로 학습
기존 세그멘테이션 모델과의 차이점
- 기존: 특정 객체 카테고리 중심의 세그멘테이션
- SAM: 객체 카테고리와 무관한 범용적 세그멘테이션
- 기존: 제한된 입력 형태
- SAM: 다양한 프롬프트 형태 지원
3. 모델 구조

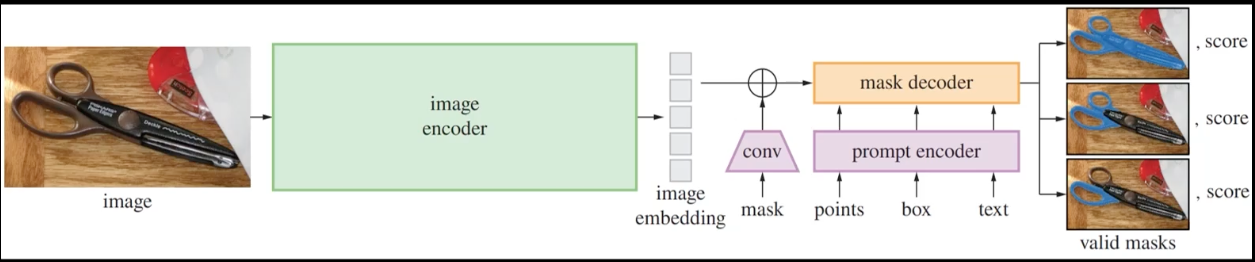
SAM의 3가지 주요 컴포넌트
- 이미지 인코더 (Image Encoder)
- ViT(Vision Transformer) 기반
- 이미지를 임베딩으로 변환
- MAE(Masked Autoencoder)로 사전 학습된 구조
- 프롬프트 인코더 (Prompt Encoder)
- 다양한 형태의 프롬프트를 임베딩으로 변환
- sparse 프롬프트(포인트, 박스 등)와 dense 프롬프트(마스크) 지원
- 위치 인코딩을 통해 공간 정보 보존
- 마스크 디코더 (Mask Decoder)
- 이미지 임베딩과 프롬프트 임베딩을 결합
- 여러 개의 트랜스포머 레이어로 구성
- 객체 마스크와 신뢰도 점수 생성
모델 크기 및 버전
- SAM-B: 91M 파라미터
- SAM-L: 308M 파라미터
- SAM-H: 636M 파라미터 (기본 버전)
4. 프롬프트 엔지니어링
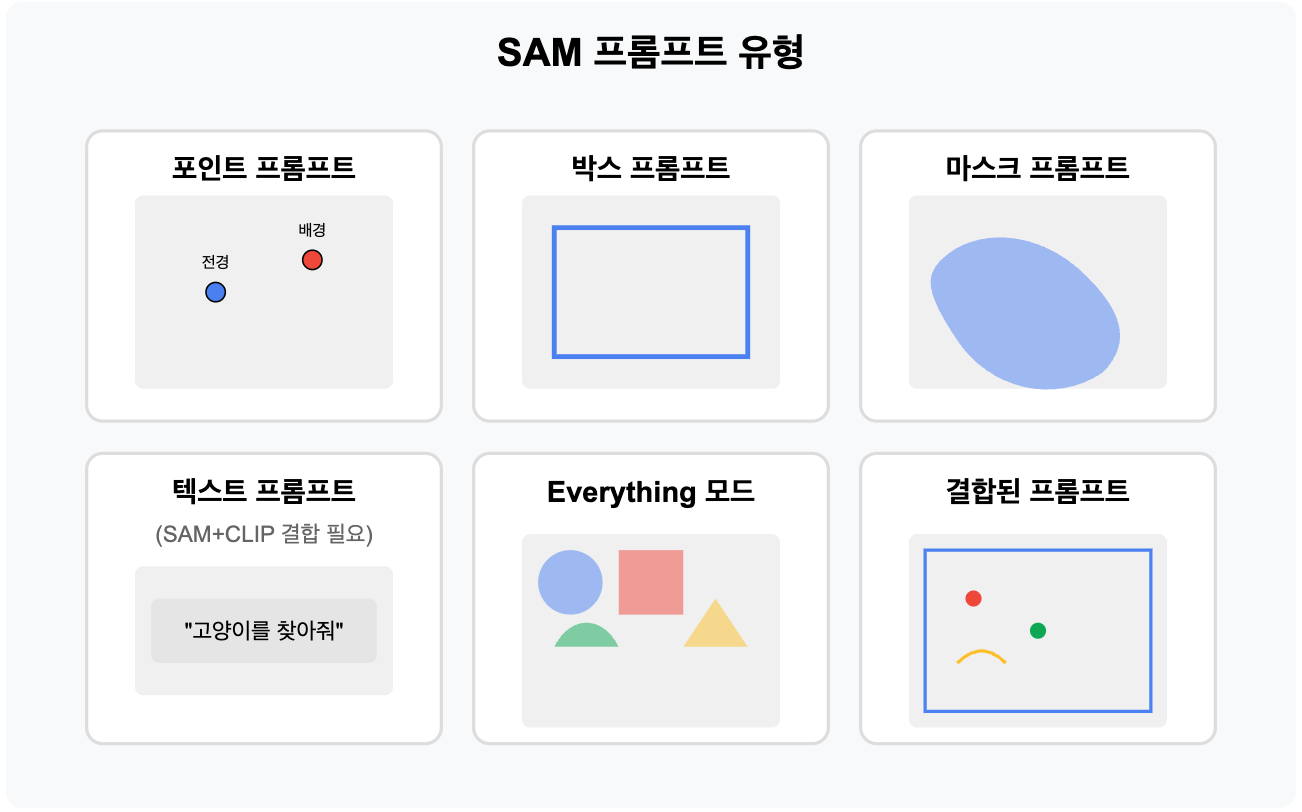
프롬프트 유형
- 포인트 프롬프트
- 이미지 내 특정 위치(x, y) 지정
- 전경/배경 포인트 구분 가능
- 여러 포인트 조합 가능
- 박스 프롬프트
- 객체를 둘러싸는 경계 상자(bounding box) 제공
- 가장 일반적이고 효과적인 프롬프트 형태
- 텍스트 프롬프트
- SAM 자체는 텍스트 프롬프트를 지원하지 않음
- CLIP과 같은 모델과 결합하여 구현 가능
- 마스크 프롬프트
- 부분적인 마스크 정보 제공
- 기존 마스크 정제에 유용
- Everything 모드
- 프롬프트 없이 이미지 내 모든 객체 세그멘테이션
5. SA-1B 데이터셋
SA-1B(Segment Anything 1-Billion) 데이터셋
- 11M 이미지, 1.1B 마스크
- 사람이 레이블링한 세계 최대 세그멘테이션 데이터셋
- 데이터 다양성 확보를 위한 전략적 수집

데이터 수집 프로세스
- 모델 지원 인터페이스: 초기 모델이 마스크 후보 제안
- 인간 검증 및 수정: 어노테이터가 마스크 검증 및 수정
- 반복적 개선: 모델과 인간의 협업을 통한 데이터셋 확장
- 품질 관리: 일관성과 정확성 보장을 위한 관리 체계
6. 활용 사례
주요 응용 분야
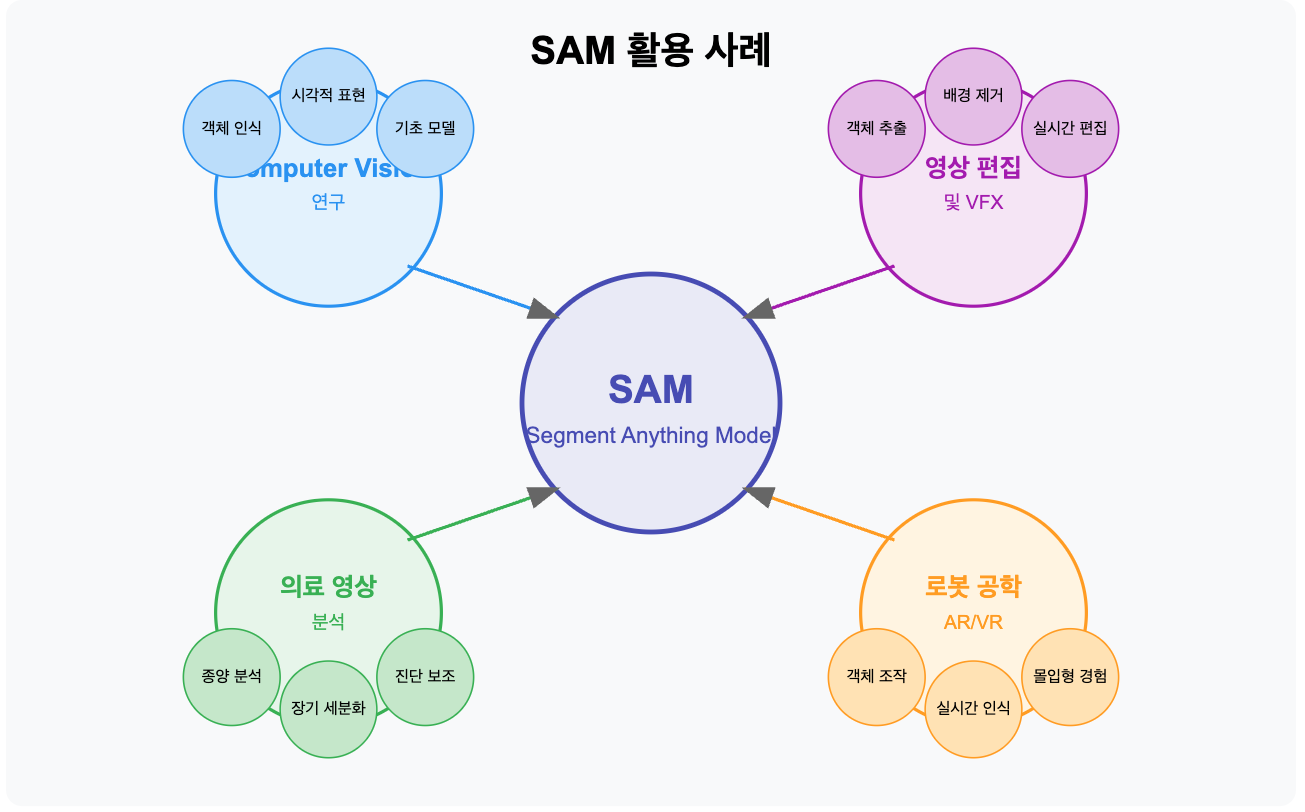
- Computer Vision 연구
- 객체 인식 및 추적
- 시각적 표현 학습
- 다양한 비전 모델의 기초 모델로 활용
- 영상 편집 및 VFX
- 대상 객체 추출 및 합성
- 배경 제거
- 실시간 편집 도구
- 의료 영상 분석
- 종양, 장기 등 의학적 구조 세그멘테이션
- 진단 보조 도구
- 로봇 공학
- 로봇의 시각적 인식 능력 향상
- 객체 조작 및 상호작용
- 증강현실/가상현실
- 실시간 객체 인식 및 상호작용
- 몰입형 경험 개선
7. 한계점
SAM의 한계
- 의미적 이해 부족
- 객체의 의미를 이해하지 못하고 시각적 경계만 분할
- "고양이"라는 개념보다는 "고양이 모양의 물체" 인식
- 복잡한 장면 처리의 어려움
- 복잡한 배경, 겹치는 객체에서 성능 저하
- 세밀한 구조(머리카락, 그물망 등) 처리 어려움
- 일관성 문제
- 유사한 프롬프트에 대해 다른 결과 생성 가능
- 모호한 경계에서의 불안정성
- 계산 자원 요구량
- 실시간 처리를 위해 강력한 하드웨어 필요
- 모바일 기기 등에서 사용 제한
8. 결론 및 향후 방향
결론
- SAM은 세그멘테이션 분야의 패러다임을 바꾸는 혁신적 모델
- 프롬프트 기반 접근과 대규모 데이터셋을 통한 강력한 성능
- 다양한 응용 분야에서 활용 가능성 입증
향후 연구 방향
- 다양한 모달리티 통합
- 텍스트, 오디오 등 다중 모달 프롬프트 지원
- SAM + CLIP과 같은 모델 결합
- 시간적 차원 확장
- 비디오 세그멘테이션으로 확장
- 객체 추적 기능 통합
- 효율성 개선
- 더 가벼운 모델 버전 개발
- 모바일 기기 등에서 실행 가능한 최적화
- 의미적 이해 강화
- 객체 카테고리 인식 능력 향상
- 장면 이해와 세그멘테이션 통합
참고 자료
'AI > 대학원' 카테고리의 다른 글
| CPU(NumPy) and GPU(CuPy and PyTorch) 성능 비교 (2) | 2024.12.23 |
|---|---|
| RNN 의 Parameter Sharing (3) | 2024.11.21 |
| PCA 와 FDA 실습 및 분석 (0) | 2024.11.20 |
| Gaussian process 실습 (8) | 2024.11.14 |
| VGG16 을 이용한 Transfer Learning 실습 (3) | 2024.11.11 |



