Abstract
이 논문에서는 Masked Autoencoders (MAE)가 컴퓨터 비전에서 확장 가능한 자가 지도 학습(Self-Supervised Learning, SSL) 방법임을 보여줍니다.
우리의 MAE 접근 방식은 간단합니다. 입력 이미지의 일부 패치를 무작위로 마스킹한 후, 손실된 픽셀을 복원하는 것입니다.
이 방법은 두 가지 핵심 설계를 기반으로 합니다.
- 비대칭 인코더-디코더(Asymmetric Encoder-Decoder) 아키텍처:
- 인코더는 마스크 토큰(mask tokens) 없이 visible patches 만 처리합니다.
- 디코더는 경량화되어 있으며, 잠재 표현(latent representation)과 마스크 토큰을 기반으로 원본 이미지를 복원합니다.
- 높은 비율(예: 75%)의 마스킹이 의미 있는 학습 효과를 가짐
- 입력 이미지의 높은 비율을 마스킹하면 비전 모델의 학습에 유의미한 자기 지도 학습(self-supervisory) 과제가 됩니다.
이러한 설계를 결합하면 대규모 모델을 효율적으로 훈련할 수 있습니다.
- 훈련 속도는 3배 이상 빨라지고, 정확도는 향상됩니다.
- 대용량 모델 학습이 가능하며, 일반화 성능(generalization)이 뛰어납니다.
- 예를 들어, ViT-Huge 모델을 ImageNet-1K 데이터에서 학습하면, 87.8%의 최고 성능을 기록했습니다.
또한 이전의 지도 학습(Supervised Pretraining) 방법보다 뛰어난 전이 학습(Transfer Learning) 성능을 보여주었으며, 모델 확장 시 성능 향상이 가능함을 확인하였습니다.

Figure 1. MAE 아키텍처 설명
- 사전 학습(Pre-training) 과정:
- 입력 이미지에서 무작위로 큰 비율(예: 75%)의 패치(Patches)를 마스킹(masking)한다.
- 인코더(Encoder)는 보이는 패치(Visible Patches)만 처리하며, 마스크 토큰(Mask Tokens)은 사용하지 않는다.
- 마스크 토큰은 인코더 이후 추가되며, 이를 포함한 전체 패치(Encoded Patches + Mask Tokens)를 디코더(Decoder)가 처리하여 원본 이미지를 픽셀 단위로 복원한다.
- 사전 학습 후(After Pre-training):
- 디코더는 폐기(Discarded)되며, 인코더만을 활용하여 완전한(마스킹되지 않은) 이미지를 입력으로 받아 인식(Recognition) 태스크에 사용된다.
1. Introduction
최근 몇 년간 딥러닝은 지속적으로 강력한 모델을 개발하며 발전해 왔습니다.
그러나 대규모 모델의 성능은 점점 더 많은 데이터와 컴퓨팅 자원을 필요로 하고 있습니다.
- 예를 들어, 기존에는 100만 개의 이미지만으로도 모델을 학습할 수 있었지만, 현재는 수억 개의 라벨링된 데이터가 필요할 정도로 데이터 요구량이 증가했습니다.
이러한 데이터 문제는 자연어 처리(NLP)에서 자가 지도 학습(Self-Supervised Learning, SSL)을 활용하여 해결되었습니다.
- 대표적인 예시는 GPT의 Autoregressive 언어 모델링과 BERT의 Masked Autoencoding 방법입니다.
- NLP 모델은 문장에서 일부 단어를 제거한 후 이를 예측하는 방식으로 일반화된 언어 모델을 학습할 수 있었습니다.
- 현재 NLP 모델은 1000억 개 이상의 파라미터를 포함하는 대규모 모델로 발전했습니다.
이러한 마스킹 오토인코더(Masked Autoencoder, MAE) 개념은 컴퓨터 비전에도 자연스럽게 적용될 수 있습니다.
그러나 비전 모델에서 마스킹 기법을 적용하는 것은 NLP와 몇 가지 차이점이 있습니다.
비전(Vision)과 NLP의 차이점
- 아키텍처의 차이 (Architectural Differences)
- 과거 비전 모델은 주로 CNN(Convolutional Neural Networks)을 기반으로 설계되었습니다.
- CNN은 규칙적인 격자 구조에서 동작하기 때문에 NLP에서 사용하는 마스크 토큰(mask tokens)이나 위치 임베딩(positional embeddings)을 쉽게 통합할 수 없었습니다.
- 그러나 최근에는 Vision Transformer (ViT)이 도입되면서 이러한 제약이 사라졌습니다.
- 정보 밀도의 차이 (Information Density Differences)
- NLP의 텍스트 데이터는 높은 의미 밀도(high semantic density)를 가지고 있습니다.
- 예를 들어, 문장에서 몇 개의 단어만 제거해도 문맥(Context)을 이해하기 어려운 문제가 발생합니다.
- 반면, 이미지 데이터는 Spatial Redundancy이 크기 때문에, 일부 픽셀이 없어도 주변 패치에서 쉽게 복원될 수 있습니다.
- 디코더의 역할 차이 (Decoder Differences)
- NLP에서 디코더는 단어(Word) 수준에서 복원을 수행하며, 이 단어는 강한 의미를 가집니다.
- 반면, 이미지에서 디코더는 픽셀(Pixel) 수준의 복원을 수행하며, 이는 일반적인 인식(Recognition) 과제보다 더 낮은 의미 수준을 가집니다.
- 따라서 이미지 데이터에서 효과적인 마스킹 학습을 위해 디코더 설계가 중요합니다.
Masked Autoencoder (MAE) 설계 원칙
이 논문에서는 간단하고 확장 가능한 형태의 MAE를 제안합니다.
- 입력 이미지에서 무작위로 일부 패치를 제거한 후, 픽셀 수준에서 복원하는 방식입니다.
- 비대칭 인코더-디코더 구조(Asymmetric Encoder-Decoder Architecture)를 도입하여 학습 효율을 높였습니다.
1) 인코더 (Encoder)
- 보이는 패치(Visible Patches)만 처리하고, 마스크 패치는 입력하지 않습니다.
- 이는 연산량을 줄이는 데 중요한 역할을 합니다.
2) 디코더 (Decoder)
- 작은 크기의 경량 디코더(Lightweight Decoder)를 사용하여 원본 이미지를 복원합니다.
- 마스크 패치를 포함하여 전체 이미지를 복원하지만, 주요한 정보는 인코더에서 추출됩니다.
이 설계를 활용하면 매우 높은 마스킹 비율(예: 75%)을 적용해도 성능 저하 없이 효율적으로 학습할 수 있습니다.
- 연산량은 3배 이상 감소하며, 모델의 성능은 향상됩니다.
- ViT-Huge를 ImageNet-1K에서 학습하면 87.8%의 최고 성능을 기록했습니다.
- 기존 지도 학습 대비 전이 학습(Transfer Learning) 성능도 향상됨을 확인했습니다.
3. Approach
우리의 마스킹 오토인코더(Masked Autoencoder, MAE)는 일부 관찰된 정보만을 사용하여 원래의 신호를 복원하는 간단한 Autoencoding 기법입니다.
- 기존의 오토인코더(Autoencoder)와 마찬가지로, 입력을 잠재 표현(Latent Representation)으로 변환하는 인코더(Encoder)와 이를 원본 데이터로 복원하는 디코더(Decoder)를 포함합니다.
- 그러나, MAE는 기존 오토인코더와 달리 비대칭 인코더-디코더 구조(Asymmetric Encoder-Decoder Architecture)를 가집니다.
- 인코더는 관찰된 일부 데이터(Visible Patches)만을 처리하며, 마스크된 데이터는 입력하지 않습니다.
- Lightweight Decoder 가 마스크된 영역을 복원합니다.
이 섹션에서는 MAE의 핵심 구성 요소들을 설명합니다.
3.1 마스킹 기법 (Masking Strategy)
우리는 Vision Transformer (ViT) [16]의 구조를 따르며, 이미지를 고정 크기의 패치(Patches)로 분할합니다.
이후, 일부 패치만을 샘플링하고, 나머지 패치는 제거(마스킹)합니다.
- 패치 샘플링은 무작위(Random Sampling) 방식을 따릅니다.
- 샘플링된 패치만 인코더에 입력되고, 마스크된 패치는 처리되지 않습니다.
왜 높은 비율(75% 이상)의 마스킹이 효과적인가?
- 일반적인 이미지 데이터는 공간적으로 중복된 정보(Spatial Redundancy)를 포함합니다.
- 낮은 마스킹 비율(예: 15~30%)에서는 손실된 패치를 주변 패치를 통해 너무 쉽게 복원할 수 있습니다.
- 75% 이상의 높은 마스킹 비율을 적용하면, 단순한 통계적 보간(Interpolation)만으로는 문제를 해결할 수 없으며, 모델이 보다 의미 있는 표현(Representation)을 학습하게 됩니다.
- 중앙 부분이 더 많이 마스킹되는 'Center Bias'를 방지하기 위해 균등 분포(Uniform Distribution)로 샘플링
효율적인 인코더 설계
- 높은 마스킹 비율 덕분에 입력 데이터가 매우 희소(Sparse)해지므로, 인코더를 더욱 효율적으로 설계할 수 있는 기회를 제공
결과적으로, 높은 마스킹 비율은 학습을 더욱 어렵게 만들지만, 이는 오히려 강력한 표현 학습을 유도하는 중요한 요소가 됩니다.


3.2 MAE Encoder
MAE의 인코더는 ViT 기반 Transformer 모델을 사용하며, 일반적인 ViT 모델과 유사한 방식으로 동작합니다.
하지만 기존의 ViT와 차별되는 중요한 특징이 있습니다.
- 인코더는 Visible Patches 만 입력으로 사용합니다.
- 마스킹된 패치는 입력으로 제공되지 않으며, 마스크 토큰(Mask Tokens)도 사용하지 않습니다.
- 즉, 인코더는 완전히 원본 패치만을 기반으로 잠재 표현(Latent Representation)을 학습합니다.
- 패치는 선형 변환(Linear Projection)과 위치 임베딩(Positional Embedding)을 거쳐 Transformer 블록으로 입력됩니다.
- 인코더는 전체 이미지의 일부(예: 25%)만 처리하므로, 연산량이 크게 감소하며 학습 속도가 향상됩니다.
결과적으로, MAE 인코더는 훨씬 적은 연산량으로도 강력한 표현 학습을 수행할 수 있습니다.
3.3 MAE Decoder
MAE의 디코더는 손실된 패치를 복원하는 역할을 담당합니다.
이 디코더는 기존의 오토인코더와 마찬가지로 잠재 표현을 기반으로 원본 이미지를 복원하는 과정을 수행하지만,
일반적인 오토인코더와 비교하여 다음과 같은 차별점이 있습니다.
MAE 디코더의 특징
- 입력으로 전체 패치를 사용합니다.
- (1) 인코더에서 처리된 보이는 패치(Visible Patch Representations)
- (2) 마스크된 패치에 대한 마스크 토큰(Mask Tokens)
- 모든 토큰(보이는 패치 + 마스크 토큰)에 위치 임베딩(Positional Embeddings)이 추가된다.
- 위치 임베딩이 없으면 마스크 토큰이 이미지 내에서 어디에 해당하는지 알 수 없기 때문이다.
- 마스크 토큰은 학습 가능한 벡터로 설정되며, Transformer 블록을 통해 처리됩니다.
- 출력은 픽셀 단위의 값을 예측하며, 이를 통해 원본 이미지를 복원합니다.
MAE 디코더의 특징 및 활용 방식
- 디코더는 사전 학습(Pre-training) 과정에서만 사용되며, 실제 인식(Recognition) 태스크에서는 사용되지 않는다.
- 따라서 인코더와 독립적으로 설계할 수 있으며, 가벼운(Lightweight) 구조를 유지하는 것이 가능하다.
- 기본적으로, MAE의 디코더는 인코더보다 훨씬 좁고 얕은(Narrower and Shallower) 구조를 가지며, 연산량이 10% 미만인 경우도 있다.
- 비대칭(Asymmetric) 설계를 통해, 전체 토큰 세트를 경량 디코더가 처리함으로써 사전 학습 시간을 크게 단축할 수 있다. 🚀
즉, 인코더는 보이는 패치만 처리하고, 디코더는 전체 패치를 복원하는 역할을 수행합니다.
이를 통해 디코더의 계산량을 최소화하고, 학습 속도를 가속화할 수 있습니다.
3.4 Reconstruction Target
MAE는 마스킹된 패치를 복원할 때 픽셀 단위의 값을 직접 예측하는 방식을 사용합니다.
- 디코더의 최종 출력층은 각 패치의 픽셀 값을 예측하는 선형 레이어(Linear Layer)로 구성됩니다.
- 손실 함수는 평균 제곱 오차(Mean Squared Error, MSE)를 활용하여 원본 이미지와 복원된 이미지를 비교합니다.
- 손실(Loss)은 오직 마스크된 패치에서만 계산됩니다. (이는 NLP의 BERT [14]와 유사한 전략입니다.)
픽셀 기반 복원의 장점
- 간단한 설계(Simple Design):
- 기존 연구(예: BEiT [2])에서는 Discrete Token(토큰 단위 예측)을 사용하지만, MAE는 픽셀 값 자체를 직접 예측합니다.
- 이를 통해 더 간단한 구조로 높은 성능을 달성할 수 있습니다.
- 추가적인 토큰화(Tokenization) 과정이 불필요함
- BEiT와 같은 기존 연구에서는 사전 학습된 VQ-VAE 토크나이저를 필요로 하지만,MAE는 그런 과정을 생략하고 바로 픽셀 복원을 수행할 수 있습니다.
3.5 Simple implementation
MAE의 사전 학습(Pre-training)은 매우 효율적으로 구현 가능하며, 특수한 희소(Sparse) 연산을 필요로 하지 않는다.
1. MAE 사전 학습 과정 (Efficient Pre-training Process)
- 각 입력 패치(Patch)를 토큰(Token)으로 변환
- 선형 변환(Linear Projection) + 위치 임베딩(Positional Embedding) 추가
- 토큰 리스트를 랜덤하게 섞음 (Shuffling Tokens)
- 마스킹 비율에 따라 마지막 부분의 토큰을 제거 (Random Sampling Without Replacement)
- 인코더는 이 보이는 패치(Visible Patches)만 입력으로 받음
- 인코딩 후, 마스크 토큰(Mask Tokens)을 추가하여 복원 과정 준비
- 원래 순서를 복원(Unshuffle)하여 모든 토큰을 원본 이미지 패치와 정렬
- 디코더(Decoder)는 전체 패치를 처리하며, 위치 임베딩을 추가하여 복원 수행
2. Computational Efficiency
- 특수한 희소 연산(Sparse Operations)이 필요 없음
- 셔플링(Shuffling) 및 언셔플링(Unshuffling) 과정이 매우 빠르며, 연산 비용이 거의 없음
- 이 단순한 구현 방식 덕분에 MAE는 효율적으로 학습 가능함
즉, MAE는 단순한 변형 연산(Shuffling, Masking)만으로도 쉽게 구현할 수 있으며, 기존의 Transformer 기반 모델과 호환성이 높습니다.
3.6 MAE의 주요 장점 (Key Benefits of MAE)
- 연산량 절감 (Computational Efficiency)
- 전체 이미지의 75% 이상을 마스킹하므로, 인코더는 25%만 처리하면 됩니다.
- 이는 학습 속도를 3배 이상 향상시키고, 메모리 사용량을 크게 감소시킵니다.
- 강력한 표현 학습 (Rich Representation Learning)
- 높은 마스킹 비율 덕분에, 단순한 공간적 보간(Interpolation) 방식으로는 복원이 어렵습니다.
- 따라서 모델이 더 깊고 의미 있는 특징(Feature)을 학습하게 됩니다.
- 전이 학습(Transfer Learning) 성능 향상
- MAE를 사전 학습한 후, 다양한 다운스트림 태스크(예: 이미지 분류, 객체 탐지)에서 지도 학습(Supervised Learning)보다 더 높은 성능을 보입니다.
결론
- MAE는 단순하지만 강력한 자기 지도 학습 방법으로, 기존 Transformer 기반 비전 모델(ViT)과 쉽게 결합할 수 있습니다.
- 픽셀 기반 복원 방식과 높은 마스킹 비율을 활용하여, 기존 대비 훨씬 효율적인 학습이 가능합니다.
4. ImageNet 실험 (ImageNet Experiments)
우리의 MAE는 ImageNet-1K (IN1K) [13] 데이터셋을 사용하여 **자가 지도 사전 학습(Self-Supervised Pretraining)**을 수행합니다.
그 후, **지도 학습(Supervised Training)**을 통해 학습된 표현(Representation)을 평가합니다.
평가 방식:
- 엔드 투 엔드 미세 조정 (End-to-End Fine-Tuning)
- MAE를 사전 학습한 후, 전체 모델을 미세 조정(Fine-Tuning)하여 최종 성능을 평가합니다.
- 선형 분류기 학습 (Linear Probing)
- 사전 학습된 인코더의 출력을 고정한 후, 새로운 선형 분류기(Linear Classifier)를 학습하여 평가합니다.
모든 실험은 단일 224×224 크롭(crop)에서 Top-1 정확도(Accuracy)를 보고하며,
더 자세한 실험 설정은 **부록(Appendix A.1)**에 정리되어 있습니다.
4.1 기본 실험: ViT-Large (Baseline: ViT-Large)
우리는 ViT-Large (ViT-L/16) [16]을 기본 실험 모델로 사용합니다.
- ViT-L은 ResNet-50보다 10배 이상 큰 모델이며, 과적합(Overfitting)되기 쉬운 경향이 있습니다.
MAE 사전 학습이 가져오는 성능 향상
학습 방식 ImageNet-1K 성능 (Top-1 Accuracy)
| 지도 학습 (Scratch, ViT 논문 [16]) | 76.5% |
| 지도 학습 (Scratch, 우리 구현) | 82.5% |
| MAE 사전 학습 후 미세 조정 | 84.9% |
- ViT-L 모델을 지도 학습(Supervised Training)만으로 학습하는 것은 어렵습니다.
- 특별한 정규화 기법(Regularization)을 적용해야 82.5% 성능을 얻을 수 있습니다.
- MAE를 활용한 사전 학습 후 미세 조정하면, 성능이 84.9%로 크게 향상됩니다.
- 더불어, 미세 조정 과정이 단 50 Epoch만 수행되어도 높은 성능을 달성할 수 있습니다.
- 이는 사전 학습된 표현(Representation)이 매우 강력함을 시사합니다.
4.2 MAE의 주요 특성 분석 (Main Properties of MAE)
1) 마스킹 비율(Masking Ratio)의 영향
(Figure 5: 마스킹 비율이 모델 성능에 미치는 영향)

마스킹 비율 vs 성능 (ImageNet-1K Top-1 정확도 %)
| 마스킹 비율 (%) | 미세 조정 (Fine-Tuning) | 선형 분류 (Linear Probing) |
| 10% | 83.0% | 54.6% |
| 40% | 84.5% | 66.1% |
| 50% | 84.9% | 69.9% |
| 75% (기본 설정) | 84.9% | 73.5% |
| 80% | 84.9% | 71.8% |
| 90% | 84.5% | 66.0% |
1. 마스킹 비율 (Masking Ratio)의 영향
- Figure 5에서 마스킹 비율이 모델 성능에 미치는 영향을 분석
- 최적의 마스킹 비율이 예상보다 훨씬 높음 (약 75%)
- 이는 NLP 모델인 BERT [14]의 마스킹 비율(15%)과 대조적
- 기존 비전 모델 연구 [6, 16, 2]에서는 20~50% 마스킹 비율을 사용했으나, MAE에서는 75%가 최적의 성능을 보임
2. 높은 마스킹 비율이 학습에 미치는 영향
- MAE는 손실된 패치를 복원할 때 단순히 선이나 텍스처를 연장하는 것이 아니라, 객체와 장면의 전체적인 구조(Gestalt)를 파악하는 방식으로 복원함
- 즉, 단순한 보간(Interpolation)이 아니라 더 높은 수준의 "추론(Reasoning)"을 통해 복원이 이루어짐
- 이는 유용한 표현(Useful Representation)을 학습하는 데 기여할 가능성이 높음
3. 선형 분류(Linear Probing) vs. 미세 조정(Fine-Tuning) 성능 비교
- Figure 5에서 선형 분류와 미세 조정이 다른 패턴을 보임
- ✅ 미세 조정(Fine-Tuning)
- 마스킹 비율에 상대적으로 덜 민감
- 40~80% 범위의 마스킹 비율에서도 성능이 안정적으로 유지됨
- 모든 미세 조정 결과가 지도 학습(Scratch) 대비 우수한 성능(82.5% 이상)을 기록함
- ✅ 선형 분류(Linear Probing)
- 마스킹 비율이 높아질수록 정확도가 점진적으로 향상됨
- 최적의 마스킹 비율에서 성능 차이가 20% 이상 발생 (54.6% → 73.5%)
2) 디코더(Decoder) 설계의 영향
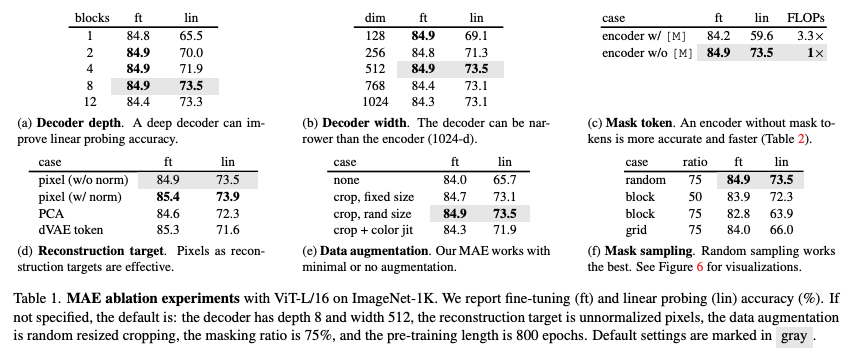
디코더 깊이 vs 성능 (ImageNet-1K Top-1 정확도 %)
| 디코더 깊이 (블록 수) | 미세 조정 (Fine-Tuning) | 선형 분류 (Linear Probing) |
| 1 블록 | 84.8% | 65.5% |
| 2 블록 | 84.9% | 70.0% |
| 4 블록 | 84.9% | 71.9% |
| 8 블록 (기본 설정) | 84.9% | 73.5% |
| 12 블록 | 84.4% | 73.3% |
- 디코더의 깊이가 깊을수록 선형 분류 성능이 향상됩니다.
- 하지만 미세 조정(Fine-Tuning)에서는 디코더 크기가 성능에 미치는 영향이 상대적으로 작습니다.
- 디코더가 너무 작아도(Few Blocks) 높은 성능을 유지할 수 있음을 확인했습니다.
즉, 디코더는 훈련 과정에서만 사용되며, 최종 모델에서는 제거되므로 매우 가볍게 설계할 수 있습니다.
3) 마스크 토큰 (Mask Token)의 역할
실험 조건 Fine-Tuning 정확도 Linear Probing 정확도 학습 속도(FLOPs)
| 인코더에서 마스크 토큰 사용 | 84.2% | 59.6% | 3.3× 느림 |
| 인코더에서 마스크 토큰 사용 안함 (MAE) | 84.9% | 73.5% | 3.3× 빠름 |
- 마스크 토큰을 인코더에서 사용하지 않을 때 더 높은 성능을 보였습니다.
- 마스크 토큰을 인코더가 처리하지 않도록 설계하면, 모델 학습 속도가 3배 이상 빨라집니다.
- 이는 인코더가 항상 실제 패치(Real Patches)만을 처리하도록 학습됨을 의미합니다.
4) 복원 대상 (Reconstruction Target)의 영향
Table 1d에서 다양한 재구성 목표(재구성 방식)에 대한 비교 실험을 수행하였다.
- 현재까지의 실험은 정규화되지 않은 픽셀(Unnormalized Pixels)을 기반으로 수행됨.
- 패치별 정규화(Per-Patch Normalization)를 적용한 경우, 정확도가 향상됨.
- 정규화는 각 패치 내에서 대비(Contrast)를 높여주는 역할을 하며, 이는 학습에 긍정적인 영향을 줌
1. PCA 기반 재구성 (PCA in Patch Space)
- 패치 공간에서 PCA(주성분 분석)를 수행하고, 가장 큰 PCA 계수(여기서는 96개)를 재구성 목표로 설정
- 그러나, 이 방식은 정확도를 저하시킴
- 이는 고주파(High-Frequency) 정보가 MAE 학습에 중요한 역할을 한다는 것을 시사함
2. 토큰 기반 재구성 (Token-Based Reconstruction, BEiT 방식 비교)
- BEiT [2]에서는 픽셀 대신 사전 학습된 DALLE의 dVAE [50]을 이용한 토큰(Token) 예측 방식을 사용
- 이를 MAE에 적용하여, 디코더가 크로스 엔트로피 손실(Cross-Entropy Loss)을 사용하여 토큰 인덱스를 예측하도록 변경
결과 비교
- Fine-Tuning 성능은 정규화되지 않은 픽셀보다 0.4% 향상됨
- 그러나 정규화된 픽셀과 비교하면 성능 차이가 없으며, 오히려 선형 분류(Linear Probing) 성능은 감소함
- §5에서 추가적으로 실험한 결과, 전이 학습(Transfer Learning)에서 토큰화를 사용할 필요가 없음을 확인함
3. 픽셀 기반 MAE vs. 토큰화(Tokenization) 방식
- 픽셀 기반 MAE는 토큰화 방식보다 훨씬 단순한 구조를 가짐
- dVAE 토크나이저를 활용하는 방식은 추가적인 사전 학습(Pre-Training)이 필요하며, 이는 추가적인 데이터(250M 이미지 [50])에 의존할 가능성이 있음
- dVAE 인코더는 ViT-L의 40%에 해당하는 추가적인 연산량(FLOPs)을 요구하며, 이는 상당한 오버헤드(Overhead)를 발생시킴
- 반면, 픽셀 기반 MAE는 이러한 문제 없이 간단하면서도 효과적인 학습이 가능함
복원 방식 Fine-Tuning 정확도 Linear Probing 정확도
| 원본 픽셀 (비정규화) | 84.9% | 73.5% |
| 정규화된 픽셀 | 85.4% | 73.9% |
| PCA 압축 | 84.6% | 72.3% |
| dVAE 토큰 | 85.3% | 71.6% |
- 픽셀 기반 복원이 가장 효과적인 학습 방식임을 확인했습니다.
- 정규화된 픽셀(Normalized Pixels)로 복원하면, 약간의 성능 향상이 있었습니다.
- 고주파 정보(High-Frequency Components)가 MAE 학습에서 중요한 역할을 함
- BEiT처럼 dVAE 토큰화를 사용하면 일부 성능 향상이 있지만, 추가적인 사전 학습 비용이 발생하고, 전이 학습에서는 필요하지 않음
5) 데이터 증강 (Data Augmentation) 실험
Table 1e에서는 MAE 사전 학습(Pre-training) 과정에서 데이터 증강(Data Augmentation)이 미치는 영향을 분석하였다.
1. MAE는 최소한의 데이터 증강으로도 잘 작동
- MAE는 단순한 크롭(Cropping)만 사용해도 좋은 성능을 발휘함
- 고정 크기(Fixed-Size) 크롭 또는
- 랜덤 크기(Random-Size) 크롭 (랜덤 수평 플리핑 포함)
- 색상 변화(Color Jittering)를 추가하면 성능이 저하됨
- 따라서 다른 실험에서는 색상 변화 증강을 사용하지 않음
2. MAE는 데이터 증강이 거의 필요 없음
- 놀랍게도, 데이터 증강을 전혀 사용하지 않아도(center-crop만 적용, 수평 플리핑 없이) MAE는 안정적인 성능을 유지
- 이는 대조 학습(Contrastive Learning)과 관련된 방법들([62, 23, 7, 21])과 매우 다른 특징
- 예를 들어, BYOL [21]과 SimCLR [7]은 데이터 증강 없이 사용할 경우, 각각 13%와 28%의 성능 저하가 발생
- 대조 학습 방식에서는 두 개의 다른 뷰(Views)가 필요하며, 데이터 증강이 없으면 모델이 무의미한 정답(Trivial Solution)에 빠질 가능성이 높음
3. MAE에서 데이터 증강의 역할은 마스킹이 대신 수행
- MAE에서는 랜덤 마스킹(Random Masking)이 데이터 증강과 같은 역할을 수행
- 각 학습 반복마다 새로운 마스크가 적용되므로, 데이터 증강이 없어도 새로운 훈련 샘플이 생성되는 효과가 있음
- 즉, 마스킹 자체가 모델 학습을 어렵게 만들며, 일반적인 데이터 증강 없이도 충분한 정규화(Regularization) 효과를 제공
결론
- MAE는 데이터 증강 없이도 안정적인 성능을 유지하며, 이는 대조 학습 방식과 매우 다른 특징
- 마스킹이 데이터 증강의 역할을 대신하며, 모델이 다양한 입력 분포를 학습할 수 있도록 함
- 기본적으로 크롭(Cropping)만 적용하고, 추가적인 색상 증강(Color Jittering)은 오히려 성능을 저하시킴
6) 마스크 샘플링 전략 (Mask Sampling Strategy) 비교
Table 1f에서는 다양한 마스크 샘플링 전략이 MAE의 성능에 미치는 영향을 비교하였다.
Figure 6을 통해 각 샘플링 방식의 차이를 시각적으로 확인할 수 있다.

1. 블록 단위 마스킹 (Block-Wise Masking, BEiT 방식 [2])
- 큰 블록 형태로 마스킹을 수행하는 방식 (Figure 6, 중앙)
- MAE에서 블록 단위 마스킹을 적용하면, 50% 마스킹에서는 괜찮은 성능을 보이지만, 75% 마스킹에서는 성능이 저하됨
- 랜덤 샘플링보다 학습 손실(Training Loss)이 더 높으며, 복원된 이미지가 더 흐릿해지는(Blurrier) 경향이 있음
- 이는 블록 단위로 넓은 영역이 제거되면, 네트워크가 학습하기 어려운 태스크로 변하기 때문
2. 그리드 단위 마스킹 (Grid-Wise Sampling)
- 일정한 간격을 두고 4개 중 1개의 패치만 유지하는 방식 (Figure 6, 우측)
- 학습 손실이 낮으며, 복원된 이미지가 더 선명(Sharper)하게 나타남
- 그러나, 표현 학습(Representation Quality)이 떨어짐
- 즉, 모델이 너무 쉽게 복원할 수 있기 때문에 보다 강력한 특징을 학습하는 데 어려움이 있음
3. 랜덤 마스킹 (Random Sampling, MAE 기본 방식)
- 랜덤하게 마스킹할 패치를 선택하는 방식
- MAE에서는 랜덤 샘플링이 가장 좋은 성능을 보임
- 75% 이상의 높은 마스킹 비율에서도 안정적인 학습이 가능
- 연산량이 줄어들면서도 정확도가 유지되는 효과가 있음 → 더 빠른 학습 속도를 제공
결론
- 블록 단위 마스킹은 학습이 더 어려우며, 75% 마스킹에서는 성능 저하가 발생
- 그리드 방식은 복원이 쉬워 학습 손실이 낮지만, 표현 학습의 질이 떨어짐
- 랜덤 샘플링이 가장 좋은 성능을 보이며, 높은 마스킹 비율에서도 효율적인 학습이 가능
5) 훈련 일정 (Training Schedule)의 영향

- 훈련 Epoch이 증가할수록 성능이 꾸준히 향상됩니다.
- 특히, Linear Probing 성능은 1600 Epoch에서도 여전히 성능이 증가하고 있음을 확인했습니다.
- 이는 MAE가 매우 긴 학습 과정에서도 지속적으로 표현 학습 성능을 개선할 수 있음을 시사합니다.
4.2 기존 방법과의 비교 (Comparisons with Previous Results)

1. 자가 지도 학습(Self-Supervised Learning) 방법과 비교
- Table 3에서 다양한 자가 지도 학습된 ViT 모델의 미세 조정(Fine-Tuning) 성능을 비교
- ViT-B 모델에서는 여러 방법들이 유사한 성능을 보임
- 그러나 ViT-L 모델에서는 방법 간 성능 차이가 더 커지며, 이는 대형 모델일수록 과적합(Overfitting)을 줄이는 것이 중요한 과제임을 시사
- MAE는 모델 크기를 쉽게 확장할 수 있으며, 더 큰 모델에서 꾸준한 성능 향상을 보임
- ViT-H(224 해상도) 모델에서는 86.9% 정확도 달성
- 448 해상도로 미세 조정하면 87.8% 정확도 달성 (ImageNet-1K 데이터만 사용)
- 기존 최고 성능(87.1%, 512 해상도 [67])보다 높은 성능을 기록
- ImageNet-1K(IN1K) 데이터만 사용하여 경쟁이 치열한 벤치마크에서 비지도 학습 SOTA를 갱신
- MAE는 BEiT [2]보다 더 높은 정확도를 제공하면서도, 구조가 더 단순하고 연산 속도가 빠름
- BEiT는 픽셀 대신 토큰을 예측하는 방식인데, BEiT 논문에서는 ViT-B에서 픽셀 복원 방식 사용 시 성능이 1.8% 하락한다고 보고됨
- MAE는 dVAE 기반의 토큰화를 사용할 필요가 없음
- 또한, MAE는 BEiT보다 학습 속도가 3.5배 빠름(Table 1c 참고)
- Table 3에서 MAE 모델들은 1600 에포크 동안 사전 학습되었으며, 이는 정확도를 높이는 데 기여
- 하지만 동일한 하드웨어에서 학습했을 때, 총 학습 시간은 다른 방법보다 적음
- 예를 들어, ViT-L 모델을 128개의 TPU-v3 코어에서 학습할 때, MAE의 1600 에포크 학습 시간은 31시간이며, MoCo v3는 300 에포크에 36시간이 소요됨 [9]
2. 지도 학습(Supervised Learning) 사전 학습과 비교
- ViT 원본 논문 [16]에서는, ViT-L 모델이 IN1K 데이터에서 학습될 때 성능이 저하됨
- 본 논문에서 구현한 지도 학습 방식(A.2 참고)은 더 나은 성능을 보이지만, 정확도가 일정 수준에서 한계(Saturation)에 도달함 (Figure 8 참고)

- 반면, MAE 사전 학습(Pre-training)은 IN1K 데이터만 사용하더라도 더 나은 일반화 성능(Generalization)을 보임
- 특히, 더 큰 모델일수록 지도 학습 대비 MAE의 성능 향상 폭이 더 큼
- 이는 JFT-300M에서 지도 학습한 ViT 모델의 성능 향상 패턴과 유사한 경향을 보임 [16]
- 즉, MAE는 모델 크기를 확장하는 데 효과적인 사전 학습 방법으로 작용할 수 있음을 시사
결론
- MAE는 BEiT보다 더 높은 정확도를 제공하며, 구조가 단순하고 3.5배 더 빠름
- 1600 에포크 동안 학습해도 다른 방법보다 총 학습 시간이 적게 소요됨
- 지도 학습과 비교했을 때, 더 큰 모델에서 성능 향상 폭이 더 크며, JFT-300M에서 학습한 모델과 유사한 성능 확장 패턴을 보임
4.3. 부분 미세 조정 (Partial Fine-Tuning)
- Table 1의 결과를 보면, 선형 분류(Linear Probing)와 전체 미세 조정(Fine-Tuning) 성능 사이에는 큰 상관관계가 없음
- 선형 분류(Linear Probing)는 최근 몇 년간 자주 사용된 평가 방법이지만, 비선형적(Non-Linear) 특징을 학습할 기회를 놓칠 수 있음
- 딥러닝의 강점은 비선형적인 표현 학습이므로, 선형 분류만으로 모델의 성능을 평가하는 것은 한계가 있음
- 이에 따라, 완전한 미세 조정(Fine-Tuning)과 선형 분류 사이의 중간 방식으로 "부분 미세 조정(Partial Fine-Tuning)"을 실험
- 일부 계층(Several Layers)만 미세 조정하고, 나머지는 고정(Freeze)하는 방식
- 이러한 기법은 과거 연구에서도 사용된 바 있음 (예: [65, 70, 42])
1. 실험 결과 (Figure 9 참고)

- Transformer 블록 한 개만 미세 조정해도 정확도가 73.5% → 81.0%로 크게 향상
- Transformer 블록의 절반(MLP 서브 블록만)을 미세 조정해도 79.1%를 기록하며, 선형 분류보다 훨씬 높은 성능을 보임
- 이 방식은 본질적으로 MLP 헤드만 미세 조정하는 방식
- 4개 또는 6개 블록을 미세 조정하면, 전체 미세 조정과 거의 동일한 성능에 도달 가능
2. MoCo v3 [9]와 비교
- Figure 9에서 MoCo v3 (대조 학습 방식)와 MAE의 부분 미세 조정 성능을 비교
- MoCo v3는 선형 분류 정확도가 높지만, 부분 미세 조정에서는 MAE가 더 나은 성능을 보임
- 예를 들어, 4개 블록을 미세 조정했을 때, MAE가 MoCo v3보다 2.6% 높은 성능을 기록
- MAE 표현은 선형적으로 구분(Linear Separability)이 덜 되지만, 비선형 특징 학습(Non-Linear Features)에서는 더 강력한 성능을 보임
- 즉, 선형 분류 정확도만으로 표현 학습(Representation Learning)의 품질을 평가하는 것은 한계가 있으며, 전이 학습(Transfer Learning) 성능을 제대로 반영하지 못할 수도 있음
3. 결론
- Transformer 블록 일부만 미세 조정해도 성능이 크게 향상되며, 선형 분류보다 효과적
- MAE는 비선형 특징 학습에서 강력한 성능을 발휘하며, MoCo v3보다 부분 미세 조정에서 우수한 결과를 보임
- 선형 분류(Linear Probing)는 모델 성능을 평가하는 유일한 기준이 될 수 없으며, 전이 학습 성능과 잘 일치하지 않을 수도 있음
5. Transfer Learning Experiments
우리는 MAE를 사전 학습한 후 다양한 다운스트림(Downstream) 태스크에서 전이 학습(Transfer Learning) 성능을 평가합니다.
이 실험에서는 객체 검출(Object Detection), 장면 분할(Semantic Segmentation), 이미지 분류(Image Classification) 등 다양한 비전 태스크를 포함합니다.
5.1 Object Detection & Segmentation
사전 학습된 모델(Table 3 참고)을 활용하여 Downstream 태스크에서 Transfer Learning 성능을 평가
Object Detection, Semantic Segmentation, Image Classification 등 다양한 비전 태스크를 포함
5.1 Object Detection & Segmentation
- Mask R-CNN [24]을 COCO 데이터셋 [37]에서 엔드 투 엔드(End-to-End)로 미세 조정(Fine-Tuning)
- ViT 백본(Backbone)은 FPN(Feature Pyramid Network) [36]과 결합하여 사용 (A.3 참고)
- Table 4의 모든 실험에서 동일한 방식 적용
- 객체 검출 성능: Box AP (APbox)
- 인스턴스 분할 성능: Mask AP (APmask)
COCO 실험 결과 비교

- MAE는 기존 지도 학습 및 자가 지도 학습 방법보다 더 높은 객체 검출(APbox) 및 인스턴스 분할(APmask) 성능을 달성했습니다.
- 특히, BEiT와 같은 토큰 예측 기반 접근 방식보다 픽셀 복원을 활용한 MAE가 더 우수한 성능을 보였습니다.
5.2 Semantic Segmentation
우리는 ADE20K [72] 데이터셋을 사용하여 장면 분할(Semantic Segmentation) 태스크를 평가합니다.
- UperNet [63] 아키텍처를 사용하여 사전 학습된 ViT 모델을 백본으로 적용합니다.
- 모델의 성능은 mIoU (Mean Intersection over Union) 점수로 평가됩니다.
ADE20K 실험 결과 비교

- MAE는 지도 학습보다 더 높은 mIoU 점수를 기록했으며, BEiT와 비교해도 우수한 성능을 보였습니다.
- 픽셀 복원 방식이 토큰 기반 예측보다 강력한 표현 학습을 가능하게 한다는 것을 확인할 수 있습니다.
5.3 Classification tasks
우리는 다양한 데이터셋을 사용하여 이미지 분류 태스크에서 MAE의 전이 학습 성능을 평가합니다.
- iNaturalist [56] 데이터셋: 실제 생물 분류 태스크
- Places [71] 데이터셋: 장면(Scene) 분류 태스크
이미지 분류 실험 결과 비교

- iNaturalist 및 Places 데이터셋에서 MAE가 기존 최고 성능을 능가하는 결과를 보였습니다.
- 특히 ViT-H (448) 모델에서 88.3%의 iNaturalist 2019 성능을 기록하며, 기존 최고 성능보다 4.2% 높은 점수를 달성했습니다.
- Places 데이터셋에서도 기존 모델 대비 더 높은 성능을 기록했습니다.
5.4 픽셀 복원 vs. 토큰 예측 비교 (Pixels vs. Tokens as MAE Targets)
우리는 MAE에서 픽셀 복원(Pixel Reconstruction) 방식과 토큰 예측(Token Prediction) 방식의 차이를 비교합니다.
- BEiT [2]에서는 dVAE 기반 토큰을 예측하는 방식을 사용하였습니다.
- 그러나 우리는 MAE에서 단순한 픽셀 기반 복원이 더 효과적인지 실험적으로 검증합니다.
픽셀 복원 vs. 토큰 예측 성능 비교

- 정규화된 픽셀(Normalized Pixel) 복원이 가장 높은 성능을 달성했습니다.
- 토큰 예측 방식(dVAE)은 픽셀 복원보다 특별한 이점이 없음을 확인했습니다.
- 즉, 픽셀을 정규화하면 dVAE 토큰을 사용할 필요가 없음
- MAE는 더 간단한 방식으로도 BEiT보다 더 높은 성능을 얻을 수 있습니다.
결론 (Conclusion)
- MAE는 다양한 다운스트림 태스크에서 뛰어난 전이 학습 성능을 보여주었습니다.
- 객체 검출, 장면 분할, 이미지 분류 등 여러 실험에서 기존 방법을 능가하는 성능을 기록했습니다.
- 픽셀 복원이 토큰 기반 예측보다 더 간단하면서도 효과적인 방법임을 확인했습니다.
6. Discussion and Conclusion
간단하면서도 확장 가능한 알고리즘이 딥러닝의 핵심이다.
- NLP에서는 단순한 자가 지도 학습(Self-Supervised Learning, SSL) 방법(예: [47, 14, 48, 4])이 모델의 크기를 기하급수적으로 확장할 수 있도록 지원한다.
- 반면, 컴퓨터 비전 분야에서는 여전히 지도 학습(Supervised Learning)이 주요한 사전 학습 방식으로 사용되고 있다. (예: [33, 51, 25, 16])
- 본 연구에서는 ImageNet 및 전이 학습 실험을 통해, NLP에서 사용된 단순한 자가 지도 학습 방식(오토인코더, Autoencoder)이 컴퓨터 비전에서도 효과적으로 확장될 수 있음을 입증하였다.
- 즉, 비전에서의 자가 지도 학습이 NLP와 유사한 발전 경로를 따를 가능성이 높다. 🚀
이미지와 언어의 근본적인 차이점
- 이미지와 언어는 본질적으로 다른 유형의 신호이므로, 이를 신중하게 다뤄야 한다.
- 언어(Language)는 단어(Word) 단위로 의미론적(Semantic) 분해가 가능하지만, 이미지(Image)는 단순한 빛의 기록일 뿐이며, 단어에 해당하는 시각적 개념이 존재하지 않는다.
- 따라서, NLP 모델이 문장에서 특정 단어를 제거하는 것과 달리, MAE는 의미적 객체(Object)를 제거하는 것이 아니라, 무작위 패치(Random Patches)를 제거하는 방식을 선택했다.
- 이러한 방식은 대부분의 경우, 하나의 의미 단위(Semantic Segment)를 제거하는 것이 아니라, 랜덤한 픽셀 블록을 제거하도록 유도한다.
- 또한, MAE는 픽셀(Pixels)을 복원하는 방식으로 학습되지만, 픽셀 자체는 개별적인 의미를 가지지 않는다.
- 하지만 Figure 4에서 볼 수 있듯이, MAE는 단순한 픽셀 복원이 아니라 복잡하고 전체적인 구조(Holistic Reconstruction)를 복원하는 경향이 있다.
- 이는 MAE가 학습 과정에서 다양한 시각적 개념(Visual Concepts)과 의미(Semantics)를 내재화했을 가능성이 높음을 시사한다.
- 우리는 이러한 내부 표현(Hidden Representation)이 풍부하게 학습되는 과정이 MAE의 강력한 성능을 뒷받침한다고 가정하며, 향후 연구에서 이를 더욱 탐구하기를 기대한다.
Broader Impacts
- 제안된 MAE 모델은 학습 데이터셋의 통계적 특성을 기반으로 콘텐츠를 예측하므로, 데이터에 존재하는 편향(Bias)이 모델에 반영될 가능성이 있다.
- 이러한 편향에는 사회적으로 부정적인 영향을 미칠 수 있는 요소들도 포함될 수 있다.
- 또한, 모델이 실제 존재하지 않는(Inexistent) 콘텐츠를 생성할 가능성도 존재한다.
- 따라서, 본 연구를 바탕으로 이미지를 생성하거나 활용하는 작업을 수행할 때, 이러한 문제들을 신중하게 고려해야 하며, 추가적인 연구가 필요하다.
'AI > 아이펠_리서치' 카테고리의 다른 글
| DETR + SAM 으로 Zero-shot Instance Segmentation 구현하기 (1) | 2025.02.19 |
|---|---|
| [논문리뷰] Segment Anything (0) | 2025.02.18 |
| [논문리뷰] ComKD-CLIP: Comprehensive Knowledge Distillation for ContrastiveLanguage-Image Pre-traning Model (0) | 2025.02.11 |
| Airflow 디버깅 및 수정내용 (1) | 2025.01.14 |
| Transformer 를 사용한 seq2seq 모델 실습 (6) | 2024.11.27 |



