개요
케창딥 7장 내용 중 사용자 정의 metric 만들기에 대한 실습과 디버깅 과정을 기록합니다.
사용자 정의 metric 만들기
개념
함수형 정의 방법과 클래스 정의 방법 2가지가 있습니다.
클래스 정의 방법은 tf.keras.metrics.Metric 클래스를 상속받아 사용자 정의 metric 을 정의할 수 있습니다.
이 방식은 상태(state)를 저장하고, update_state, result, reset_states 메서드를 구현하여 유연하게 동작 합니다.
코드 예제
import tensorflow as tf
# 사용자 정의 메트릭 클래스
class CustomMetric(tf.keras.metrics.Metric):
def __init__(self, name="custom_metric", **kwargs):
super(CustomMetric, self).__init__(name=name, **kwargs)
self.total = self.add_weight(name="total", initializer="zeros")
self.count = self.add_weight(name="count", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
# 업데이트 로직: 예제는 절대 오차 누적합
values = tf.abs(y_true - y_pred)
self.total.assign_add(tf.reduce_sum(values))
self.count.assign_add(tf.cast(tf.size(y_true), tf.float32))
def result(self):
# 결과 계산
return self.total / self.count
def reset_states(self):
# 상태 초기화
self.total.assign(0.0)
self.count.assign(0.0)
# 모델 컴파일 시 사용
model.compile(
optimizer='adam',
loss='mse',
metrics=[CustomMetric()] # 사용자 정의 메트릭 클래스 사용
)
주요 특징
- 상태를 저장할 수 있어 복잡한 메트릭 계산에 유용합니다.
- add_weight 로 내부 상태 변수를 정의하고 update_state에서 이를 업데이트합니다.
- result에서 최종 metric 결과를 반환하며, reset_states는 학습 반복 간 초기화를 수행합니다.
함수형 정의와 비교
| 특징 | 함수형 정의 | 클래스 정의 |
| 구현 난이도 | 간단함 | 복잡함 |
| 상태 저장 | 불가능 | 가능 |
| 복잡한 계산 처리 | 어려움 | 유리함 |
| 사용 사례 | 간단한 메트릭 (예: MAE, 정확도) | 복잡한 메트릭 (예: F1-Score, Precision 등) |
F1-Score 만들기
케창딥 4장에 나오는 영화 리뷰 분류 예제를 바탕으로 F1-Score 를 만들어 metric 을 연결하고 결과를 확인 합니다.

- 필요 모듈 import
from tensorflow.keras.datasets import imdb
from tensorflow import keras
from tensorflow.keras import layers, models, callbacks
import tensorflow as tf
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score
- imdb 데이터 로드
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
- 훈련 데이터 (train_data)와 테스트 데이터 (test_data):
- 이 데이터셋은 영화 리뷰 텍스트를 정수 시퀀스로 변환한 것입니다.
- 각 정수는 영화 리뷰에서 사용된 단어의 고유 인덱스를 나타내며, 사전에 정의된 순서로 단어를 매핑합니다.
- 데이터는 리스트 형태로, 각 리뷰는 고유한 길이를 가질 수 있으며 단어 인덱스가 포함되어 있습니다.
- 훈련 레이블 (train_labels)와 테스트 레이블 (test_labels):
- 각 영화 리뷰에는 레이블이 0 또는 1로 제공됩니다.
- 0은 부정적인 리뷰, 1은 긍정적인 리뷰를 나타냅니다.
- IMDB 데이터셋 정보:
- 데이터셋의 단어들은 빈도수가 높은 순으로 인덱스를 부여받습니다. max_features = 10000 옵션을 사용하여 상위 10,000개의 빈도수가 높은 단어만 사용하도록 제한했습니다.
- 데이터는 (훈련 데이터, 훈련 레이블), (테스트 데이터, 테스트 레이블) 형태로 나누어져 있으며, 이를 통해 모델을 훈련하고 평가할 수 있습니다.
- 데이터 샘플:
- train_data[0]의 출력은 정수 시퀀스의 리스트로, 하나의 영화 리뷰를 정수로 표현한 것입니다.
- train_labels[0]은 해당 리뷰가 긍정적인지(1) 부정적인지(0)를 나타냅니다.
- 데이터 준비
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
train_data = vectorize_sequences(train_data)
test_data = vectorize_sequences(test_data)
- vectorize_sequences() 함수는 주어진 시퀀스를 멀티-핫 인코딩하여 2차원 벡터로 변환합니다.
- 결과 벡터는 리뷰의 단어가 사용되었는지 여부를 나타내는 이진 벡터입니다.
- 이는 신경망 모델이 입력으로 받을 수 있는 형태로 텍스트 데이터를 전처리하는 과정입니다.
# 학습 데이터(train_data)에서 40%를 검증 데이터로 분리
train_data, val_data, train_labels, val_labels = train_test_split(train_data, train_labels, test_size=0.4, random_state=42)
- F1 Score class 구현
class MyMetric(tf.keras.metrics.Metric):
def __init__(self, name="f1_score", **kwargs):
"""
F1 Score를 계산하는 사용자 정의 Metric 클래스.
- F1 Score는 Precision과 Recall의 조화 평균으로 정의 됨
- Metric 클래스 초기화 시 True Positives, False Positives, False Negatives를 초기화
Args:
- name (str): Metric 이름 (기본값은 "f1_score").
- **kwargs: 기타 Metric 관련 인자.
"""
super().__init__(name=name, **kwargs)
# True Positives, False Positives, False Negatives를 저장하는 상태 변수 생성
self.true_positives = self.add_weight(name="tp", initializer="zeros")
self.false_positives = self.add_weight(name="fp", initializer="zeros")
self.false_negatives = self.add_weight(name="fn", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
"""
매 배치(batch)에서 True Positives, False Positives, False Negatives를 업데이트
Args:
- y_true: 실제 라벨 (0 또는 1).
- y_pred: 모델의 예측값 (0 또는 1).
- sample_weight: 각 샘플에 가중치를 줄 때 사용하는 선택적 인자.
"""
# y_true와 y_pred를 float32로 변환
threshold = 0.5 # 최적의 값으로 설정
y_pred = tf.cast(y_pred > threshold, tf.float32)
# y_pred = tf.cast(tf.round(y_pred), tf.float32)
y_true = tf.cast(y_true, tf.float32)
# True Positives: y_true와 y_pred가 모두 1인 경우
self.true_positives.assign_add(tf.reduce_sum(y_true * y_pred))
# False Positives: y_true가 0이고 y_pred가 1인 경우
self.false_positives.assign_add(tf.reduce_sum((1 - y_true) * y_pred))
# False Negatives: y_true가 1이고 y_pred가 0인 경우
self.false_negatives.assign_add(tf.reduce_sum(y_true * (1 - y_pred)))
def result(self):
"""
F1 Score 계산:
- Precision = True Positives / (True Positives + False Positives)
- Recall = True Positives / (True Positives + False Negatives)
- F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
Returns:
- F1 Score 값.
"""
# Precision 계산 (양성 예측 중 실제 양성의 비율)
precision = self.true_positives / (self.true_positives + self.false_positives + 1e-7)
# Recall 계산 (실제 양성 중 올바르게 예측된 비율)
recall = self.true_positives / (self.true_positives + self.false_negatives + 1e-7)
# F1 Score 계산 (Precision과 Recall의 조화 평균)
return 2 * ((precision * recall) / (precision + recall + 1e-7))
def reset_states(self):
"""
Metric 상태를 초기화합니다. (에폭 시작 시 호출됨)
- True Positives, False Positives, False Negatives 값을 0으로 초기화.
"""
self.true_positives.assign(0)
self.false_positives.assign(0)
self.false_negatives.assign(0)
- Test Model 정의
- 간단한 신경망 구조 모델 정의
# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
- 컴파일 및 훈련
- 구현한 MyMetric 을 metrics 에 추가 함
# metrics 에 MyMetric() 에 추가
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels))
- 위 결과를 보면 MyMetric에서 사용자 정의 지표로 구현한 f1_score 값이 출력이 되나 그 값이 0.5 근방에서 머물고 있는게 이상하다!
- 디버깅을 위해서 아래와 같이 callback 함수를 통해 Sklearn 과 Manual 로 f1_score 값을 구할 수 있는 class 를 만들어 추가 한다.
- 비교 할 F1 Score class 구현
# Define unified callback for both sklearn and manual metric calculations
class CombinedMetricsCallback(callbacks.Callback):
def __init__(self, val_data):
super().__init__()
self.val_data = val_data
def on_epoch_end(self, epoch, logs=None):
y_pred = (self.model.predict(self.val_data[0]) > 0.5).astype(int)
y_true = self.val_data[1]
# Sklearn metrics
precision_sklearn = precision_score(y_true, y_pred)
recall_sklearn = recall_score(y_true, y_pred)
f1_sklearn = f1_score(y_true, y_pred)
print(f"Epoch {epoch + 1} - sklearn Precision: {precision_sklearn:.4f}, Recall: {recall_sklearn:.4f}, F1 Score: {f1_sklearn:.4f}")
# Manual metrics calculation using TensorFlow for consistency
true_positives = tf.reduce_sum(tf.cast(y_true * y_pred, tf.float32))
false_positives = tf.reduce_sum(tf.cast((1 - y_true) * y_pred, tf.float32))
false_negatives = tf.reduce_sum(tf.cast(y_true * (1 - y_pred), tf.float32))
precision_manual = true_positives / (true_positives + false_positives + 1e-7)
recall_manual = true_positives / (true_positives + false_negatives + 1e-7)
f1_manual = 2 * (precision_manual * recall_manual) / (precision_manual + recall_manual + 1e-7)
print(f"Epoch {epoch + 1} - Manually Precision: {precision_manual.numpy():.4f}, Recall: {recall_manual.numpy():.4f}, F1 Score: {f1_manual.numpy():.4f}")
- CombinedMetricsCallback 을 callbacks 에 연결
# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# metrics 에 MyMetric() 에 추가
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])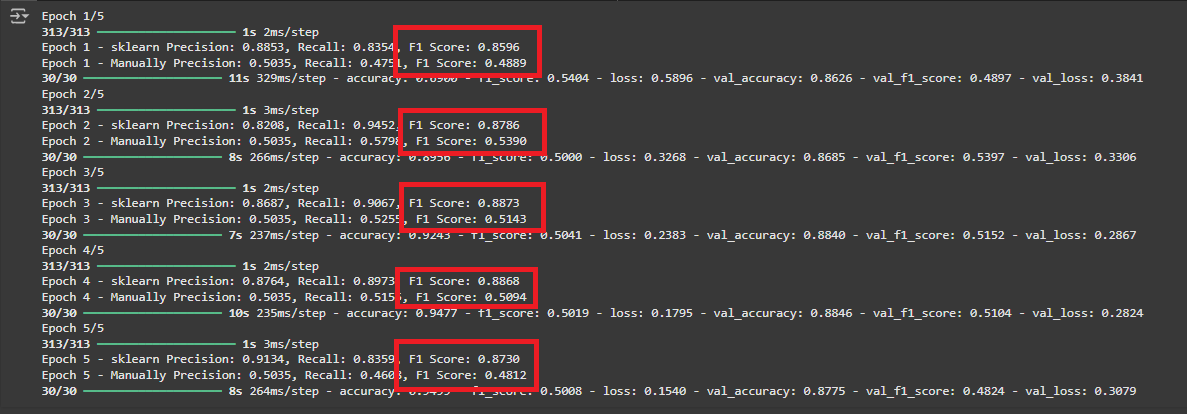
- 위 값을 비교해 보니 역시나 epoch 마다 sklearn 과 Manual F1 Score 값이 너무 차이가 많이 난다!!
- Manual 함수에서 TP, FP, FN 을 직접 구하지 않고 confusion_matrix 를 이용해서 F1 Score 를 구하도록 수정 하고 디버깅 한다.
- 디버깅을 위해 TP, FP, FN 을 출력한다.
- sklearn 의 confusion_matrix 를 사용한 CombinedMetricsCallback 구현
from sklearn.metrics import confusion_matrix
# Define unified callback for both sklearn and manual metric calculations
class CombinedMetricsCallback(callbacks.Callback):
def __init__(self, val_data):
super().__init__()
self.val_data = val_data
def on_epoch_end(self, epoch, logs=None):
y_pred = (self.model.predict(self.val_data[0]) > 0.5).astype(int)
y_true = self.val_data[1]
# Sklearn metrics
precision_sklearn = precision_score(y_true, y_pred)
recall_sklearn = recall_score(y_true, y_pred)
f1_sklearn = f1_score(y_true, y_pred)
print(f"Epoch {epoch + 1} - sklearn Precision: {precision_sklearn:.4f}, Recall: {recall_sklearn:.4f}, F1 Score: {f1_sklearn:.4f}")
# Manual metrics calculation using confusion_matrix
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
# Logging true positive, false positive, and false negative counts
print(f"Epoch {epoch + 1} - True Positives: {tp}, False Positives: {fp}, False Negatives: {fn}")
precision_manual = tp / (tp + fp + 1e-7)
recall_manual = tp / (tp + fn + 1e-7)
f1_manual = 2 * (precision_manual * recall_manual) / (precision_manual + recall_manual + 1e-7)
print(f"Epoch {epoch + 1} - Manually Precision: {precision_manual:.4f}, Recall: {recall_manual:.4f}, F1 Score: {f1_manual:.4f}")# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# metrics 에 MyMetric() 에 추가
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])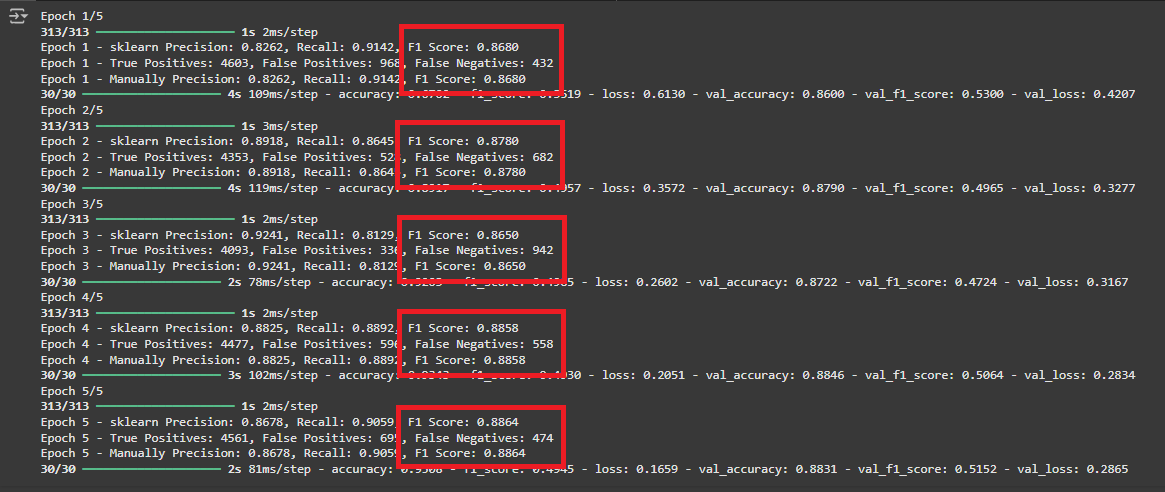
- 역시 예상대로 confusion_matrix 로 계산한 결과는 동일 하게 나왔다!
- F1 Score 계산식에는 문제가 없다는 소리이고 precision 과 recall 값이 이상하게 나온다는 소리다!
- y_pred 와 y_true 의 shape 을 확인한다.
- 디버깅을 위해 TP, FP, FN 을 출력 할 수 있게 수정 한다.
- 디버깅 코드 추가
# Define unified callback for both sklearn and manual metric calculations
class CombinedMetricsCallback(callbacks.Callback):
def __init__(self, val_data):
super().__init__()
self.val_data = val_data
def on_epoch_end(self, epoch, logs=None):
y_pred = (self.model.predict(self.val_data[0]) > 0.5).astype(int)
y_true = self.val_data[1]
print(f"y_true shape: {y_true.shape}, y_pred shape: {y_pred.shape}")
# Sklearn metrics
precision_sklearn = precision_score(y_true, y_pred)
recall_sklearn = recall_score(y_true, y_pred)
f1_sklearn = f1_score(y_true, y_pred)
print(f"Epoch {epoch + 1} - sklearn Precision: {precision_sklearn:.4f}, Recall: {recall_sklearn:.4f}, F1 Score: {f1_sklearn:.4f}")
# Manual metrics calculation using TensorFlow for consistency
true_positives = tf.reduce_sum(tf.cast(y_true * y_pred, tf.float32))
false_positives = tf.reduce_sum(tf.cast((1 - y_true) * y_pred, tf.float32))
false_negatives = tf.reduce_sum(tf.cast(y_true * (1 - y_pred), tf.float32))
# Logging true positive, false positive, and false negative counts
print(f"Epoch {epoch + 1} - True Positives: {true_positives.numpy()}, False Positives: {false_positives.numpy()}, False Negatives: {false_negatives.numpy()}")
precision_manual = true_positives / (true_positives + false_positives + 1e-7)
recall_manual = true_positives / (true_positives + false_negatives + 1e-7)
f1_manual = 2 * (precision_manual * recall_manual) / (precision_manual + recall_manual + 1e-7)
print(f"Epoch {epoch + 1} - Manually Precision: {precision_manual.numpy():.4f}, Recall: {recall_manual.numpy():.4f}, F1 Score: {f1_manual.numpy():.4f}")# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# Compile the model with custom metric
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])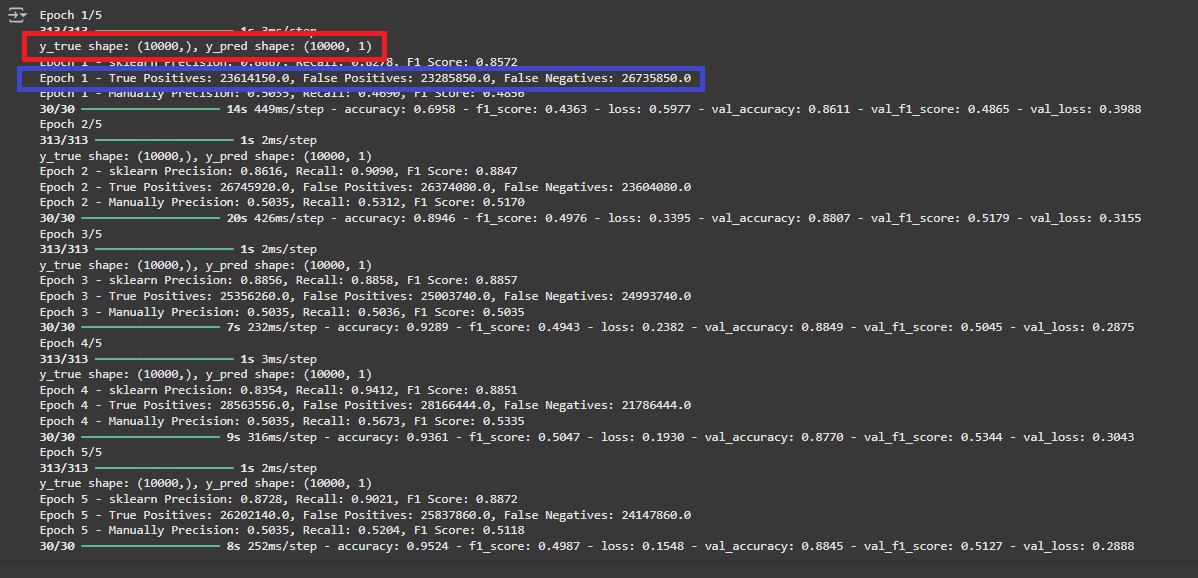
- 역시 TP, FP, FN 값 자체가 이상하다!
- shape 을 찍어보면 y_true shape: (10000,), y_pred shape: (10000, 1) 으로 shape 이 다르다!!!!!
- y_pred 를 reshape 로 shape 을 맞춰준다.
- Flatten y_pred to match y_true's shape
# Define unified callback for both sklearn and manual metric calculations
class CombinedMetricsCallback(callbacks.Callback):
def __init__(self, val_data):
super().__init__()
self.val_data = val_data
def on_epoch_end(self, epoch, logs=None):
y_pred = (self.model.predict(self.val_data[0]) > 0.5).astype(int)
y_pred = y_pred.reshape(-1) # Flatten y_pred to match y_true's shape
y_true = self.val_data[1]
print(f"y_true shape: {y_true.shape}, y_pred shape: {y_pred.shape}")
# Sklearn metrics
precision_sklearn = precision_score(y_true, y_pred)
recall_sklearn = recall_score(y_true, y_pred)
f1_sklearn = f1_score(y_true, y_pred)
print(f"Epoch {epoch + 1} - sklearn Precision: {precision_sklearn:.4f}, Recall: {recall_sklearn:.4f}, F1 Score: {f1_sklearn:.4f}")
# Manual metrics calculation using TensorFlow for consistency
true_positives = tf.reduce_sum(tf.cast(y_true * y_pred, tf.float32))
false_positives = tf.reduce_sum(tf.cast((1 - y_true) * y_pred, tf.float32))
false_negatives = tf.reduce_sum(tf.cast(y_true * (1 - y_pred), tf.float32))
# Logging true positive, false positive, and false negative counts
print(f"Epoch {epoch + 1} - True Positives: {true_positives.numpy()}, False Positives: {false_positives.numpy()}, False Negatives: {false_negatives.numpy()}")
precision_manual = true_positives / (true_positives + false_positives + 1e-7)
recall_manual = true_positives / (true_positives + false_negatives + 1e-7)
f1_manual = 2 * (precision_manual * recall_manual) / (precision_manual + recall_manual + 1e-7)
print(f"Epoch {epoch + 1} - Manually Precision: {precision_manual.numpy():.4f}, Recall: {recall_manual.numpy():.4f}, F1 Score: {f1_manual.numpy():.4f}")# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# Compile the model with custom metric
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])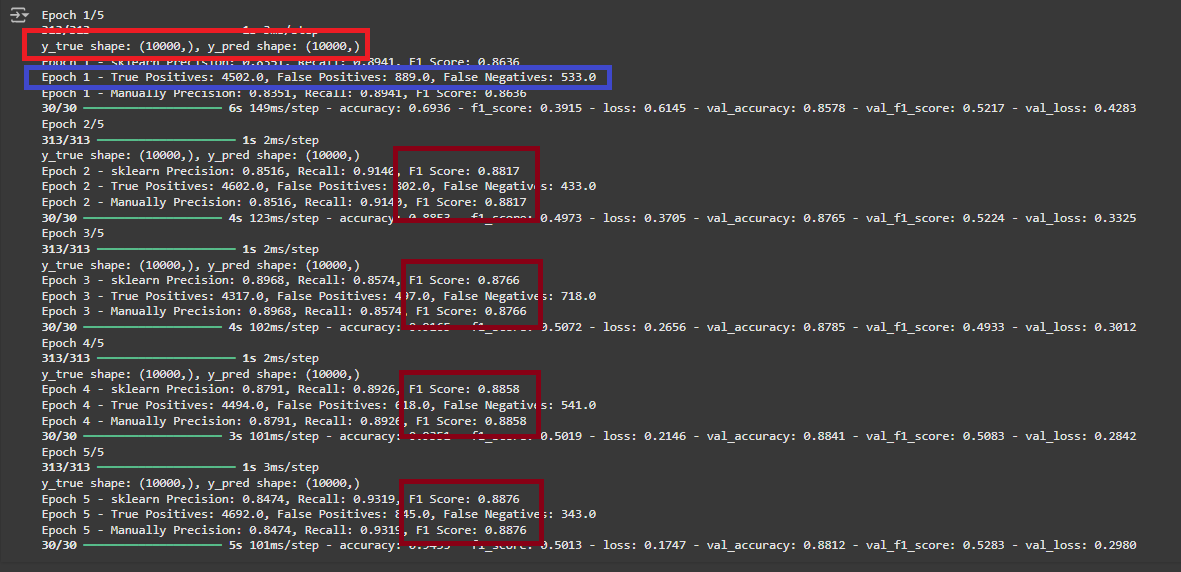
- shape 을 맞추니 드디어 동일한 계산값이 나왔다!!
- Sklearn F1 Score 는 자체적으로 confusion_matrix 계산전에 shape 을 맞추어서 계산 하도록 구현 되어 있는 걸로 추정 된다.
- manual_confusion_matrix 로 함수를 만들어 재사용 가능 하도록 수정 하였다.
- y_true와 y_pred를 F1 Score 계산을 위해 모두 tf.float32로 변환하고, 차원을 맞추기 위해 tf.reshape()를 사용한다.
- manual_confusion_matrix 함수 작성
# Function to calculate confusion matrix manually
def manual_confusion_matrix(y_true, y_pred):
# Ensure y_true and y_pred are integers and of the same shape
y_true = tf.cast(tf.reshape(y_true, [-1]), tf.float32)
y_pred = tf.cast(tf.reshape(y_pred, [-1]), tf.float32)
true_positives = tf.reduce_sum(y_true * y_pred)
false_positives = tf.reduce_sum((1 - y_true) * y_pred)
true_negatives = tf.reduce_sum((1 - y_true) * (1 - y_pred))
false_negatives = tf.reduce_sum(y_true * (1 - y_pred))
return true_negatives, false_positives, false_negatives, true_positives# Define unified callback for both sklearn and manual metric calculations
class CombinedMetricsCallback(callbacks.Callback):
def __init__(self, val_data):
super().__init__()
self.val_data = val_data
def on_epoch_end(self, epoch, logs=None):
y_pred = (self.model.predict(self.val_data[0]) > 0.5).astype(int)
y_true = self.val_data[1]
# Sklearn metrics
precision_sklearn = precision_score(y_true, y_pred)
recall_sklearn = recall_score(y_true, y_pred)
f1_sklearn = f1_score(y_true, y_pred)
print(f"Epoch {epoch + 1} - sklearn Precision: {precision_sklearn:.4f}, Recall: {recall_sklearn:.4f}, F1 Score: {f1_sklearn:.4f}")
# Manual metrics calculation using manual_confusion_matrix
tn, fp, fn, tp = manual_confusion_matrix(y_true, y_pred)
# Logging true positive, false positive, and false negative counts
print(f"Epoch {epoch + 1} - True Positives: {tp.numpy()}, False Positives: {fp.numpy()}, False Negatives: {fn.numpy()}")
precision_manual = tp / (tp + fp + 1e-7)
recall_manual = tp / (tp + fn + 1e-7)
f1_manual = 2 * (precision_manual * recall_manual) / (precision_manual + recall_manual + 1e-7)
print(f"Epoch {epoch + 1} - Manually Precision: {precision_manual.numpy():.4f}, Recall: {recall_manual.numpy():.4f}, F1 Score: {f1_manual.numpy():.4f}")# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# Compile the model with custom metric
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=5, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])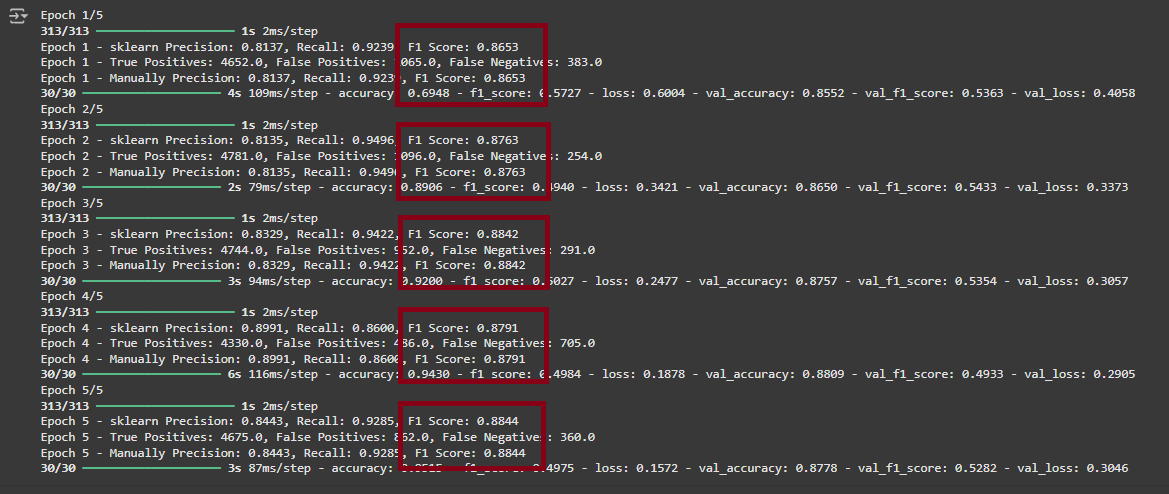
- CombinedMetricsCallback 는 정상적으로 수정이 되었다.
- 마지막으로 사용자 정의 지표로 만든 MyMetric 을 수정 한다.
- MyMetric 수정
class MyMetric(tf.keras.metrics.Metric):
def __init__(self, name="f1_score", **kwargs):
"""
F1 Score를 계산하는 사용자 정의 Metric 클래스.
- F1 Score는 Precision과 Recall의 조화 평균으로 정의 됨
- Metric 클래스 초기화 시 True Positives, False Positives, False Negatives를 초기화
Args:
- name (str): Metric 이름 (기본값은 "f1_score").
- **kwargs: 기타 Metric 관련 인자.
"""
super().__init__(name=name, **kwargs)
# True Positives, False Positives, False Negatives를 저장하는 상태 변수 생성
self.true_positives = self.add_weight(name="tp", initializer="zeros")
self.false_positives = self.add_weight(name="fp", initializer="zeros")
self.false_negatives = self.add_weight(name="fn", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
"""
매 배치(batch)에서 True Positives, False Positives, False Negatives를 업데이트
Args:
- y_true: 실제 라벨 (0 또는 1).
- y_pred: 모델의 예측값 (0 또는 1).
- sample_weight: 각 샘플에 가중치를 줄 때 사용하는 선택적 인자.
"""
# y_true와 y_pred를 float32로 변환
threshold = 0.5 # 최적의 값으로 설정
# Flatten y_pred to match y_true's shape
y_pred = tf.cast(tf.reshape(y_pred, [-1]) > threshold, tf.int32)
y_true = tf.cast(tf.reshape(y_true, [-1]), tf.int32)
# True Positives: y_true와 y_pred가 모두 1인 경우
self.true_positives.assign_add(tf.reduce_sum(y_true * y_pred))
# False Positives: y_true가 0이고 y_pred가 1인 경우
self.false_positives.assign_add(tf.reduce_sum((1 - y_true) * y_pred))
# False Negatives: y_true가 1이고 y_pred가 0인 경우
self.false_negatives.assign_add(tf.reduce_sum(y_true * (1 - y_pred)))
def result(self):
"""
F1 Score 계산:
- Precision = True Positives / (True Positives + False Positives)
- Recall = True Positives / (True Positives + False Negatives)
- F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
Returns:
- F1 Score 값.
"""
# Precision 계산 (양성 예측 중 실제 양성의 비율)
precision = self.true_positives / (self.true_positives + self.false_positives + 1e-7)
# Recall 계산 (실제 양성 중 올바르게 예측된 비율)
recall = self.true_positives / (self.true_positives + self.false_negatives + 1e-7)
# F1 Score 계산 (Precision과 Recall의 조화 평균)
return 2 * ((precision * recall) / (precision + recall + 1e-7))
def reset_states(self):
"""
Metric 상태를 초기화합니다. (에폭 시작 시 호출됨)
- True Positives, False Positives, False Negatives 값을 0으로 초기화.
"""
self.true_positives.assign(0)
self.false_positives.assign(0)
self.false_negatives.assign(0)# Build the model
model = models.Sequential([
layers.Input(shape=(10000,)),
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
# Compile the model with custom metric
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy", MyMetric()])
# Train the model with the combined callback
combined_metrics_callback = CombinedMetricsCallback((val_data, val_labels))
history = model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(val_data, val_labels),
callbacks=[combined_metrics_callback])
# Sklearn test_data F1 Score 계산
y_pred = model.predict(test_data)
y_true = test_labels
f1_sklearn = f1_score(y_true, (y_pred > 0.5).astype(int))
print(f"Sklearn F1 Score: {f1_sklearn}")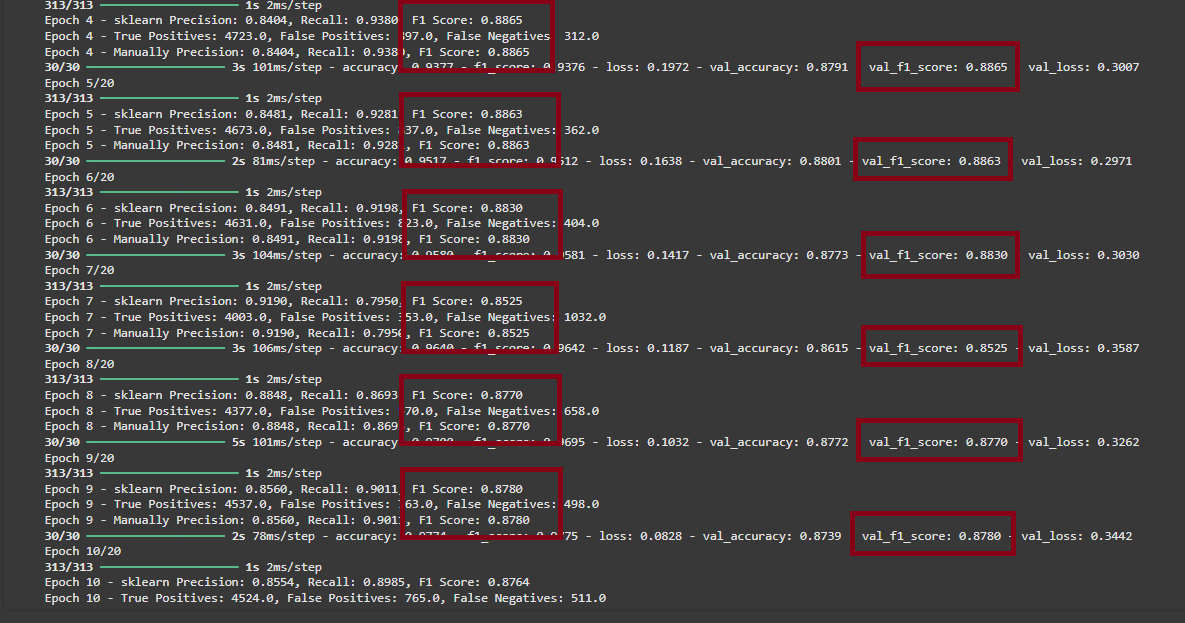
드디어 val_f1_score 와 sklearn F1 Score 가 동일하게 나온다!!
'AI > 아이펠_리서치' 카테고리의 다른 글
| Transformer Decoder 구현 및 학습 (1) | 2024.11.26 |
|---|---|
| Transformer Encoder 구현 및 학습 (2) | 2024.11.25 |
| KerasTuner 와 Tensorboard 로 HyperParameter 시각화하기 (1) | 2024.11.23 |
| CNN 과 RNN 대표 모델 (3) | 2024.11.09 |
| Generative Agents: Interactive Simulacra of Human Behavior 리뷰 (14) | 2024.10.26 |



