개요
딥러닝의 가장 대표적인 CNN 과 RNN 모델을 간략 하게 정리 해 본다.
CNN : LeNet, AlexNet, VGGNet, GoogleNet, ResNet
1. LeNet(1998)
- 최초의 CNN 모델 중 하나로, 손글씨 숫자 인식에 사용됨.
- Convolutional Layer와 Pooling Layer를 교대로 사용하며, Fully Connected Layer로 연결되는 구조.

Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, "Gradient-based learning applied to document recognition," in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791
https://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
- LeNet-5는 Convolution layer와 pooling layer, Fully connected Layer 3개의 구조를 가지는 모델입니다.. 이미지 분류를 위해 입력 이미지를 input으로 받고 Conv Layer와 Pooling Layer을 통해 이미지의 feature을 추출한 후, fully connected layer을 통해 분류하는 모델입니다.
2. AlexNet (2012)
- 딥러닝이 주목받는 계기가 된 모델로, 5개의 Convolutional Layer와 3개의 Fully Connected Layer로 구성
- ReLU 활성화 함수와 Dropout을 도입하여 학습 성능 향상.
A. Krizhevsky, I. Sutskever and G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks," in Advances in Neural Information Processing Systems (NIPS), 2012.
- AlexNet은 2012년 ImageNet 대회에서 우승하며 딥러닝의 가능성을 널리 알린 모델입니다.
- 구성: 5개의 Convolutional Layer와 3개의 Fully Connected Layer로 이루어져 있으며, 특히 Relu 활성화 함수와 Dropout 기법을 도입하여 신경망 학습에서 과적합을 방지했습니다.
- ReLU 활성화는 비선형성을 높이고 학습 속도를 크게 향상시켰으며, Dropout은 네트워크 일부를 무작위로 차단하여 과적합을 줄였습니다.
- 특징: 다중 GPU를 사용하여 병렬 처리를 통해 학습 시간을 크게 단축하고 메모리 제약을 극복 했습니다.
3. VGGNet (2014)
- 16~19개의 깊은 층을 쌓아 네트워크의 깊이와 성능 간의 관계를 조사.
- 3x3 Convolution Layer 를 여러 개 쌓는 단순하고 일관된 구조를 사용.

K. Simonyan and A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," in International Conference on Learning Representations (ICLR), 2015.
- VGGNet은 단순하고 일관된 구조를 유지한 채 네트워크 깊이를 깊게 쌓는 방식으로 딥러닝 성능을 향상시켰습니다.
- 구성: 3x3 Convolution Layer 를 여러 번 쌓아 깊은 네트워크(16~19개의 계층)를 형성하며, 각 레이어가 필터 크기와 패턴을 동일하게 유지하여 네트워크가 안정적으로 학습할 수 있게 했습니다.
- 특징: 상대적으로 깊이가 깊지만 간단한 구조로 인해 성능이 높아졌으며, 동일한 필터 크기와 Pooling을 사용하여 일관성을 유지했습니다.
4. GoogLeNet (Inception) (2014)
- 다양한 크기의 필터(1x1, 3x3, 5x5)를 동시에 적용하는 Inception 모듈을 사용하여 다양한 수준의 특징을 추출
C. Szegedy et al., "Going deeper with convolutions," 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015, pp. 1-9, doi: 10.1109/CVPR.2015.7298594.
GoogLeNet은 인셉션(Inception) 모듈을 도입하여 여러 크기의 필터(1x1, 3x3, 5x5)를 동시에 적용함으로써, 다양한 규모의 특징을 추출할 수 있는 능력을 갖추었습니다.
- 구성: Inception 모듈은 서로 다른 크기의 필터를 병렬적으로 적용한 후 그 결과를 연결하는 방식으로 구성됩니다.
- 특징: 네트워크가 깊어지더라도 1x1 Convolution을 통해 차원을 축소하여 계산 비용을 줄였고, 효율적인 학습이 가능해졌습니다.
- 2014년 ILSVRC에서 우승을 차지한 최초의 모델이 Inception v1이며, 그 이후 개선된 Inception v2, v3 등이 나온 바 있습니다.
5. ResNet (2015)
- 매우 깊은 네트워크 학습을 위해 Residual Connection을 도입.
- Skip Connection을 사용해 기울기 소실 문제를 해결하고 네트워크의 깊이를 대폭 증가시킴.
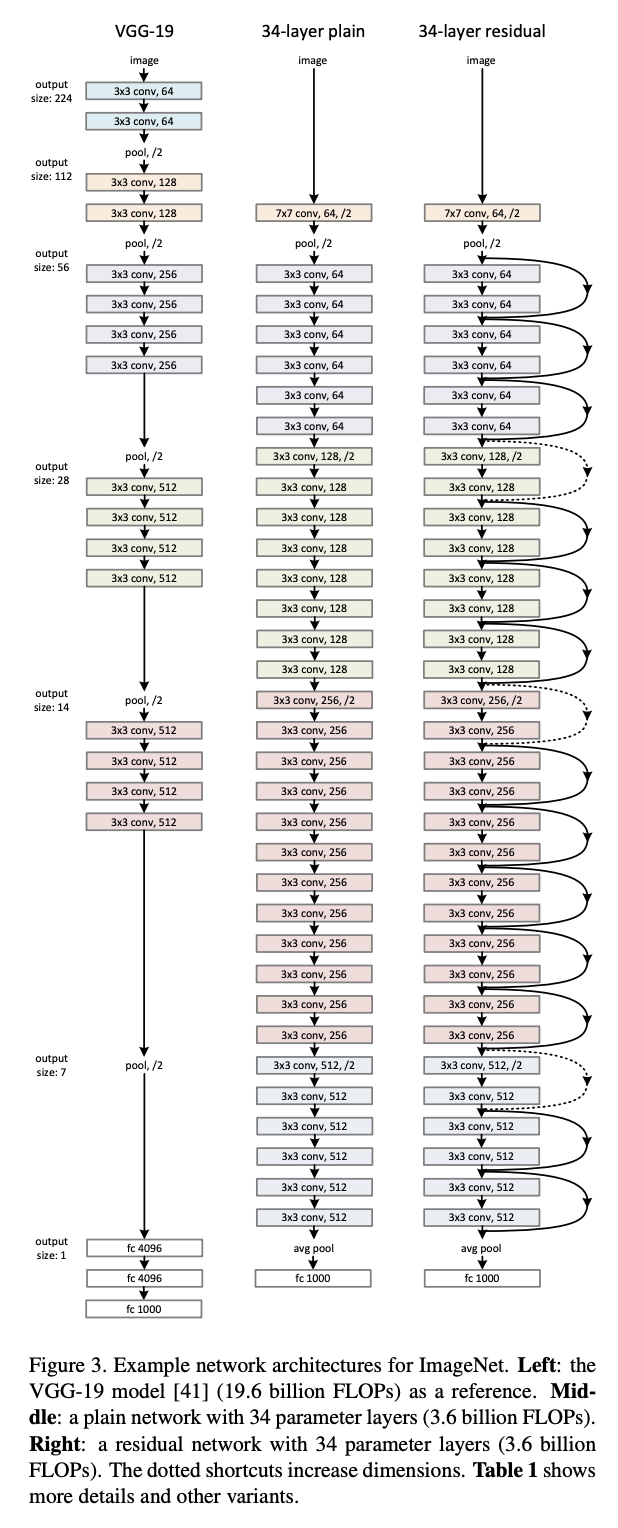
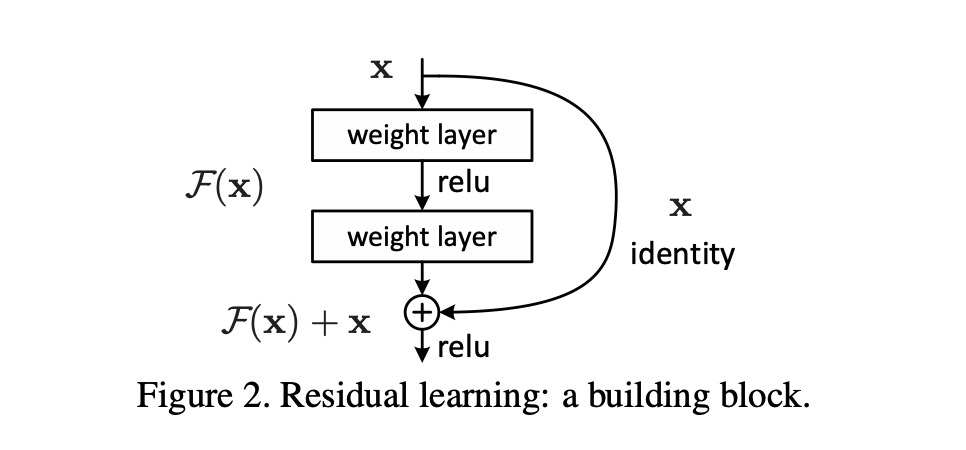
K. He, X. Zhang, S. Ren and J. Sun, "Deep Residual Learning for Image Recognition," 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
- ResNet은 딥러닝 모델이 깊어질 때 발생하는 Gradient vanishing 문제를 해결하기 위해 Residual Connection 을 도입했습니다.
- 구성: 일반적인 레이어를 거쳐 출력된 값을 다음 레이어로 직접 전달하는 Skip Connection을 추가하여, 잔차를 학습함으로써 깊은 네트워크도 효과적으로 학습할 수 있게 했습니다.
- 특징: 잔차 연결 덕분에 모델이 더 깊어질수록 성능이 개선되었고, 심지어 100개 이상의 계층을 가진 네트워크도 학습할 수 있었습니다.
- ResNet v2
- Pre-Activation 구조: ResNet v2는 기존 ResNet의 구조에서 Batch Normalization과 ReLU 활성화 함수의 순서를 변경하여 성능을 개선했습니다.
- 기존 ResNet에서는 Convolution 후 Batch Normalization을 수행했지만, ResNet v2에서는 Batch Normalization과 ReLU를 Convolution 전에 수행합니다.
- 이를 통해 더 깊은 네트워크에서 기울기 소실 문제를 더욱 효과적으로 완화하며, 학습이 용이해졌습니다
RNN : Vanilla RNN, LSTM, GRU, BiRNN, Seq2Seq
1. Vanilla RNN (1980s)
- 가장 기본적인 RNN 구조로, 이전 타임스텝의 은닉 상태를 다음 단계로 전달. 장기 의존성(long-term dependency) 문제와 기울기 소실 문제로 긴 시퀀스 학습이 어려움.
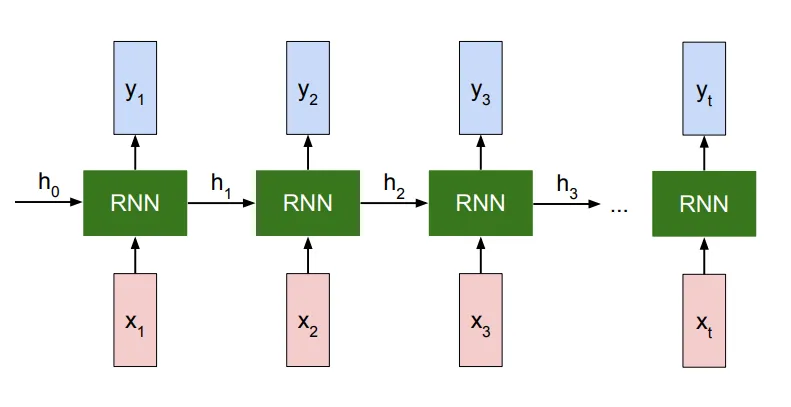
J. L. Elman, "Finding structure in time," in Cognitive Science, vol. 14, no. 2, pp. 179-211, 1990.
- Vanilla RNN은 가장 기본적인 형태의 순환 신경망으로, 시퀀스 데이터의 시간적 의존성을 처리하기 위해 이전 타임스텝의 은닉 상태를 다음 타임스텝에 전달합니다.
- 구성: 각 타임스텝에서 동일한 가중치를 사용하여 시퀀스 데이터를 처리합니다.
- 문제점: 장기 의존성(long-term dependency)을 학습할 때 기울기 소실(vanishing gradient) 문제가 발생하여 긴 시퀀스 학습에 어려움이 있습니다.
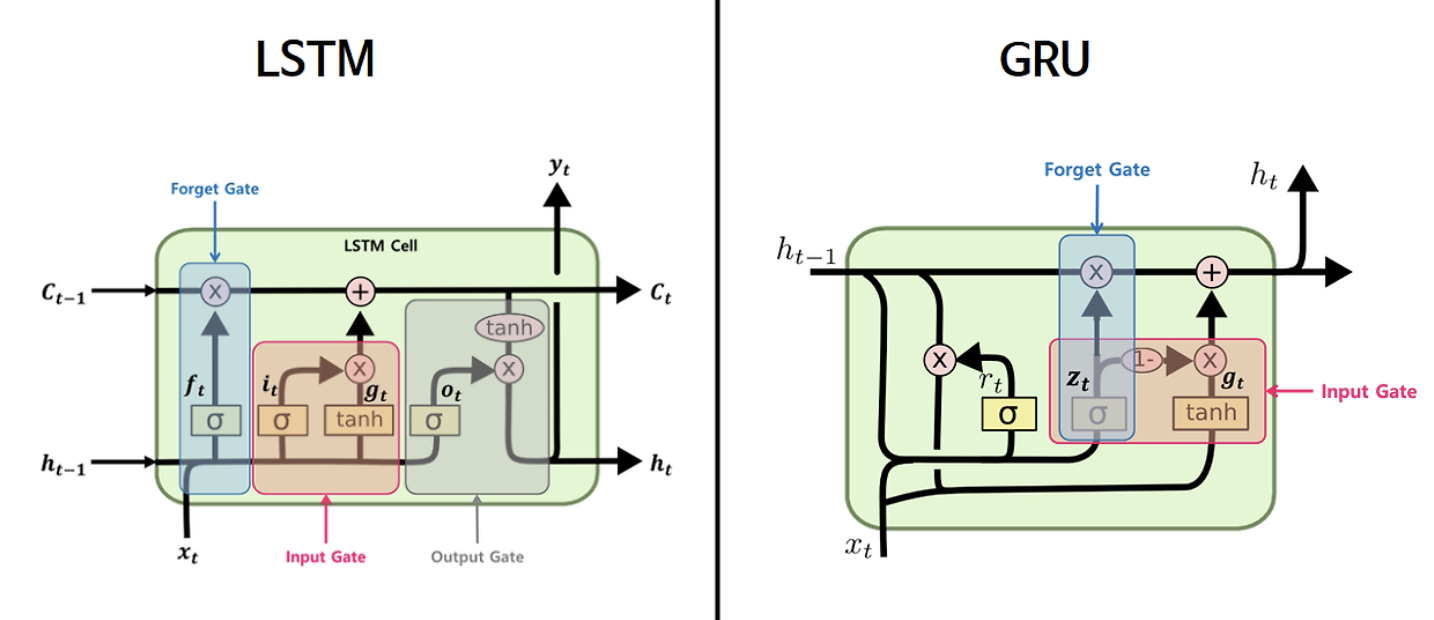
2. LSTM (Long Short-Term Memory) (1997)
- 장기 의존성(long-term dependency) 문제를 해결하기 위해 기억 셀(cell)과 게이트 구조(입력, 출력, 망각 게이트)를 도입. 기억의 저장과 삭제를 제어하여 긴 시퀀스를 잘 학습할 수 있음.
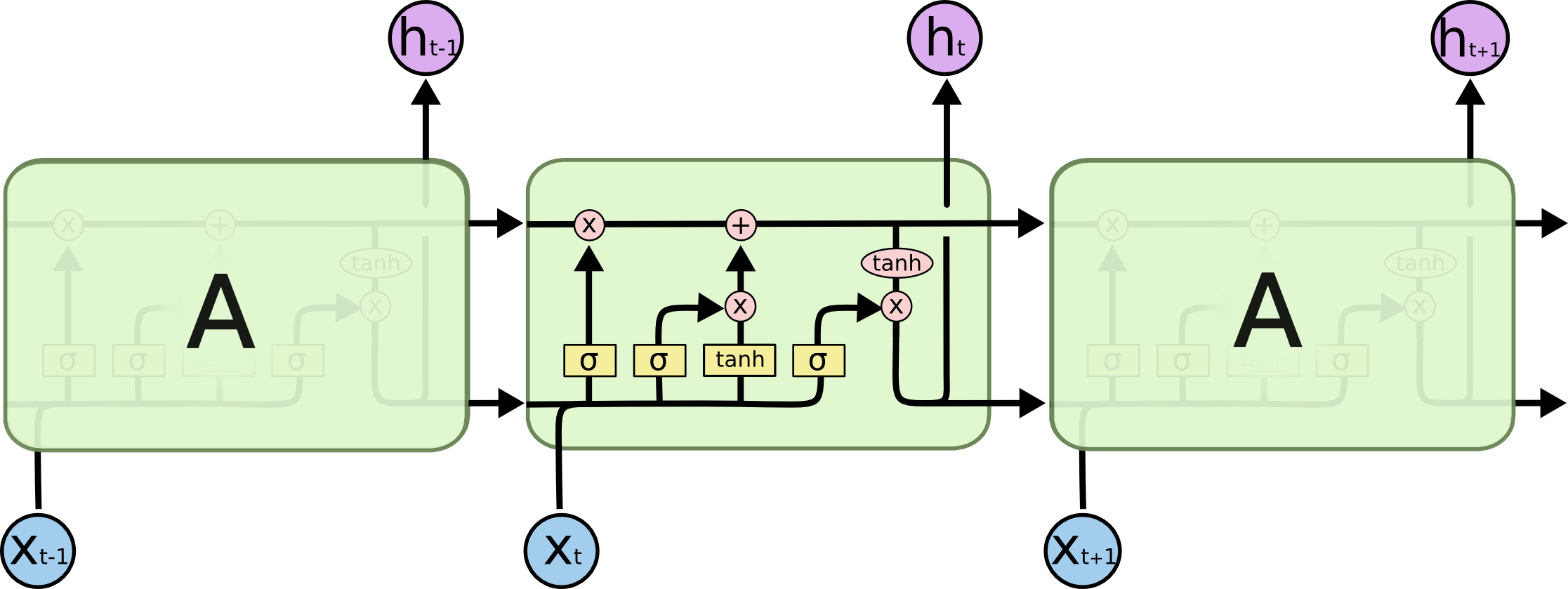
출처 : https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
S. Hochreiter and J. Schmidhuber, "Long Short-Term Memory," in Neural Computation, vol. 9, no. 8, pp. 1735-1780, 1997, doi: 10.1162/neco.1997.9.8.1735
- LSTM은 long-term dependency 문제를 해결하기 위해 기억 cell 과 gate 구조(Forget Gate, Input Gate, Output Gate)를 도입하여, 장기 및 단기 정보를 모두 학습할 수 있도록 설계되었습니다.
- 구성: LSTM의 핵심은 셀 상태(cell state)로, 이를 통해 중요한 정보를 유지하거나 불필요한 정보를 삭제하여 장기 의존성 문제를 해결합니다.
3. GRU (Gated Recurrent Unit) (2014)
- GRU는 LSTM에서 사용되는 여러 게이트 구조를 단순화한 버전으로, 업데이트 게이트와 리셋 게이트만을 사용하여 계산 비용을 줄였습니다.
- 특징: GRU는 계산이 간단하여 LSTM에 비해 적은 메모리와 시간이 소요되며, 많은 경우 LSTM과 유사한 성능을 보입니다.
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk and Y. Bengio, "Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation," in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, doi: 10.3115/v1/D14-1179
https://arxiv.org/pdf/1406.1078
- LSTM은 기존 RNN의 문제였던 Long-term dependency 문제를 해결하면서 긴 sequence를 가진 data에서도 좋은 성능을 내는 모델이지만, 복잡한 구조때문에 RNN에 비해 더 많은 parameters를 가지게 되었다. 이런 parameter을 줄이기 위해 LSTM을 간소화한 것이 GRU이다.
4. Bidirectional RNN (BiRNN) (2015)
- 순방향과 역방향 RNN을 사용하여 입력 시퀀스를 양방향으로 학습. 과거와 미래의 정보를 동시에 활용하여 더 많은 문맥 정보를 학습.

M. Schuster and K. K. Paliwal, "Bidirectional Recurrent Neural Networks," in IEEE Transactions on Signal Processing, vol. 45, no. 11, pp. 2673-2681, Nov. 1997, doi: 10.1109/78.650093
- BiRNN은 순방향과 역방향의 두 개의 RNN을 사용하여 입력 시퀀스를 양방향으로 학습합니다.
- 구성: 입력 시퀀스의 과거와 미래 정보를 모두 활용하여 더 풍부한 문맥 정보를 학습할 수 있습니다.
- 이는 특히 자연어 처리(NLP) 작업에서 효과적인 접근 방식입니다.
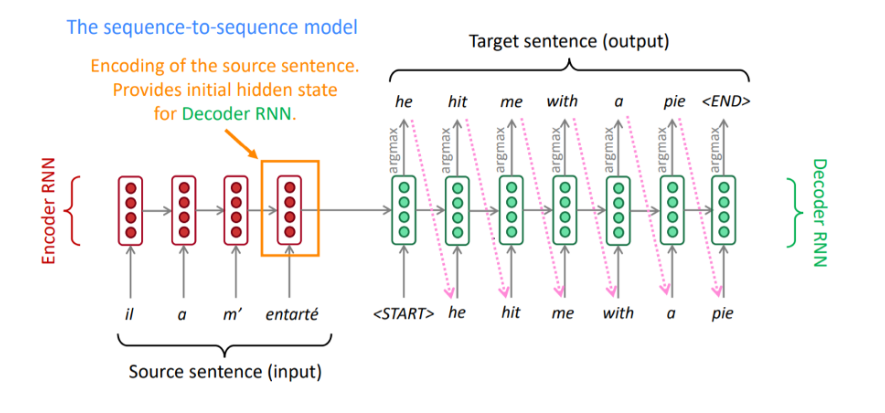
5. Seq2Seq (2014)
- 입력 시퀀스를 인코딩하여 고정 길이의 벡터(context vector)로 변환하고, 이 벡터를 기반으로 다른 형태의 시퀀스를 출력하는 구조
- 인코더와 디코더라는 두 가지 주요 구성 요소로 이루어져 있으며, LSTM이나 GRU와 같은 순환 신경망이 주로 사용
I. Sutskever, O. Vinyals, Q. V. Le, "Sequence to Sequence Learning with Neural Networks," in Advances in Neural Information Processing Systems (NIPS), 2014.
- 입력 시퀀스가 인코더에 들어가고, 인코더는 이를 고정된 벡터로 압축하여 디코더에 전달합니다.
- 디코더는 이 벡터와 이전 타임스텝의 출력을 사용하여 시퀀스의 다음 단어를 예측합니다.
- 이 과정은 목표 시퀀스 전체가 생성될 때까지 반복됩니다.
- Seq2Seq 모델은 고정된 컨텍스트 벡터의 한계를 가지고 있으며, 이를 해결하기 위해 Attention Mechanism이 도입되어 더 나은 성능을 발휘할 수 있게 되었습니다.
- Seq2Seq 모델은 기계 번역, 텍스트 요약, 음성 인식 등 시퀀스 기반 문제에 널리 사용됩니다.
'AI > 아이펠_리서치' 카테고리의 다른 글
| Transformer Decoder 구현 및 학습 (1) | 2024.11.26 |
|---|---|
| Transformer Encoder 구현 및 학습 (2) | 2024.11.25 |
| KerasTuner 와 Tensorboard 로 HyperParameter 시각화하기 (1) | 2024.11.23 |
| TensorFlow 사용자 정의 metric 만들기 (1) | 2024.11.17 |
| Generative Agents: Interactive Simulacra of Human Behavior 리뷰 (14) | 2024.10.26 |



