
개요
두 문제는 인공 신경망에서 학습을 방해하는 중요한 문제로, 각기 다른 메커니즘과 원인에서 발생합니다. 문제의 원인과 차이점을 명확히 알아보겠습니다.
1. Vanishing Gradient 문제
- 정의: 역전파(backpropagation) 과정에서 가중치 업데이트를 위한 gradient(기울기)가 층을 지나면서 점점 작아져, 최종적으로는 거의 0에 가까워지는 문제를 말합니다. 이로 인해 네트워크의 초기 층은 거의 학습되지 않게 됩니다.
- 발생 원인: 주로 sigmoid 또는 tanh 같은 활성화 함수에서 발생하며, 이 함수들은 특정 입력 값에서 기울기가 매우 작기 때문에 역전파 과정에서 gradient 가 소멸하는 경향이 있습니다.
- 영향: gradient 가 소멸되면서 가중치 업데이트가 제대로 이루어지지 않아, 모델이 학습을 효과적으로 하지 못하게 됩니다. 특히 깊은 신경망에서 많이 발생하며, 네트워크가 깊어질수록 더 심각해집니다.
- 해결 방법:
- ReLU와 같은 활성화 함수 사용
- Batch Normalization 적용
- 가중치 초기화를 잘 설정 (예: Xavier 초기화, He 초기화)
Vanishing Gradient 문제의 근본 원인
- sigmoid 나 tanh 같은 활성화 함수는 출력 범위가 제한되어 있습니다. 예를 들어, sigmoid 는 (0, 1) 범위로 출력이 제한되며, 입력 값이 크거나 작을수록 기울기 값이 0에 가까워지게 됩니다.
- 역전파에서 각 층을 거칠 때마다 이러한 작은 기울기 값들이 곱해지면, 결과적으로 최종 기울기 값이 거의 0에 가까워지게 되어, 초기층이 학습되지 않는 문제가 발생합니다. 이 문제가 바로 Vanishing Gradient 문제입니다.
역전파 과정에서 기울기 계산
- 학습에서 역전파(backpropagation)는 비용 함수의 기울기를 각 가중치에 대해 계산하여, 이 기울기를 이용해 가중치를 업데이트하는 방식입니다.
- 이때, 각 층의 기울기(gradient)는 그 층의 활성화 함수의 미분 값과 이전 층에서 전달된 기울기의 곱으로 표현됩니다.
실제 값 예시
- 활성화 함수 미분 값: sigmoid 함수의 최대 미분 값은 0.25입니다. 이는 출력이 0.5일 때 발생합니다.
- 각 층에서의 기울기 계산을 위해 매 층에서 미분 값이 0.1 정도로 나온다고 가정해 보겠습니다.
역전파 계산
- 출력층에서 계산된 기울기가 0.1 이라고 가정합니다.
- 첫 번째 은닉층에서 역전파로 기울기를 전파합니다:
- 첫 번째 은닉층 기울기 = 0.1 × 0.1 = 0.01
- 두 번째 은닉층으로 전파합니다:
- 두 번째 은닉층 기울기 = 0.01 × 0.1 = 0.001
- 세 번째 은닉층으로 전파합니다:
- 세 번째 은닉층 기울기 = 0.001 × 0.1 = 0.0001
- Output Layer: 기울기가 0.1로 시작합니다.
- Hidden Layer 1: 기울기가 0.1×0.1 로 줄어듭니다.
- Hidden Layer 2: 이전 층의 기울기와 활성화 함수의 미분 값 (0.1)을 곱하여 0.001이 됩니다.
- Hidden Layer 3: 기울기가 다시 줄어들어 0.001×0.1=이 됩니다.
기울기 소멸의 결과
- 위의 예에서 볼 수 있듯이, 각 층을 거치면서 기울기 값이 계속 작아지는 현상을 관찰할 수 있습니다.
- 출력층에서 시작한 기울기 값이 0.1이었지만, 각 층을 지날 때마다 계속 곱해져 세 번째 은닉층에서는 0.0001이 되었습니다.
- 이렇게 기울기가 점점 작아지면, 초기층의 가중치가 거의 업데이트되지 않게 되고, 이는 결국 네트워크의 학습이 매우 느려지거나 멈추는 원인이 됩니다.
해결 방법
- 이 문제를 해결하기 위해 ReLU와 같은 활성화 함수가 사용됩니다. ReLU는 입력이 양수일 때 기울기가 1이므로 기울기 소멸 문제가 덜 발생합니다.
- 또한, Batch Normalization이나 가중치 초기화 방법(Xavier, He 초기화) 같은 기법들도 기울기 소멸 문제를 완화하는 데 도움이 됩니다.
sigmoid 함수와 미분값 시각화
# 시그모이드 함수 및 그 미분값 정의
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# x 값의 범위 설정
x = np.linspace(-10, 10, 400)
# 시그모이드와 미분 값 계산
y_sigmoid = sigmoid(x)
y_derivative = sigmoid_derivative(x)
# 그래프 생성
plt.figure(figsize=(12, 6))
# 시그모이드 함수 그래프
plt.plot(x, y_sigmoid, label='Sigmoid Function', color='b')
# 시그모이드 미분 값 그래프
plt.plot(x, y_derivative, label='Sigmoid Derivative', color='r', linestyle='--')
# 그래프 설정
plt.xlabel('x', fontsize=12)
plt.ylabel('Value', fontsize=12)
plt.title('Sigmoid Function and Its Derivative', fontsize=15)
plt.axhline(0, color='black', lw=0.5)
plt.axvline(0, color='black', lw=0.5)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 그래프 표시
plt.show()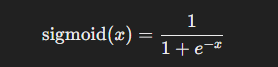
여기 그래프에서 파란색 곡선은 sigmoid 함수를, 빨간색 점선은 sigmoid 함수의 미분 값을 나타냅니다.
- sigmoid 함수는 입력 값에 따라 (0, 1) 범위 내의 출력을 가지며, 입력 값이 클수록 1에 가까워지고, 작을수록 0에 가까워집니다.
- sigmoid 함수의 미분 값은 출력이 0.5 부근에서 최대치(0.25)를 가지며, 입력 값이 너무 크거나 작으면 미분 값이 0에 가까워지는 것을 볼 수 있습니다. 이것이 Vanishing Gradient 문제의 주요 원인 중 하나입니다.
tanh 함수와 미분값 시각화
# tanh 함수 및 그 미분값 정의
def tanh(x):
return np.tanh(x)
def tanh_derivative(x):
return 1 - np.tanh(x)**2
# tanh와 그 미분 값 계산
y_tanh = tanh(x)
y_tanh_derivative = tanh_derivative(x)
# 그래프 생성
plt.figure(figsize=(12, 6))
# tanh 함수 그래프
plt.plot(x, y_tanh, label='tanh Function', color='b')
# tanh 미분 값 그래프
plt.plot(x, y_tanh_derivative, label='tanh Derivative', color='r', linestyle='--')
# 그래프 설정
plt.xlabel('x', fontsize=12)
plt.ylabel('Value', fontsize=12)
plt.title('tanh Function and Its Derivative', fontsize=15)
plt.axhline(0, color='black', lw=0.5)
plt.axvline(0, color='black', lw=0.5)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 그래프 표시
plt.show()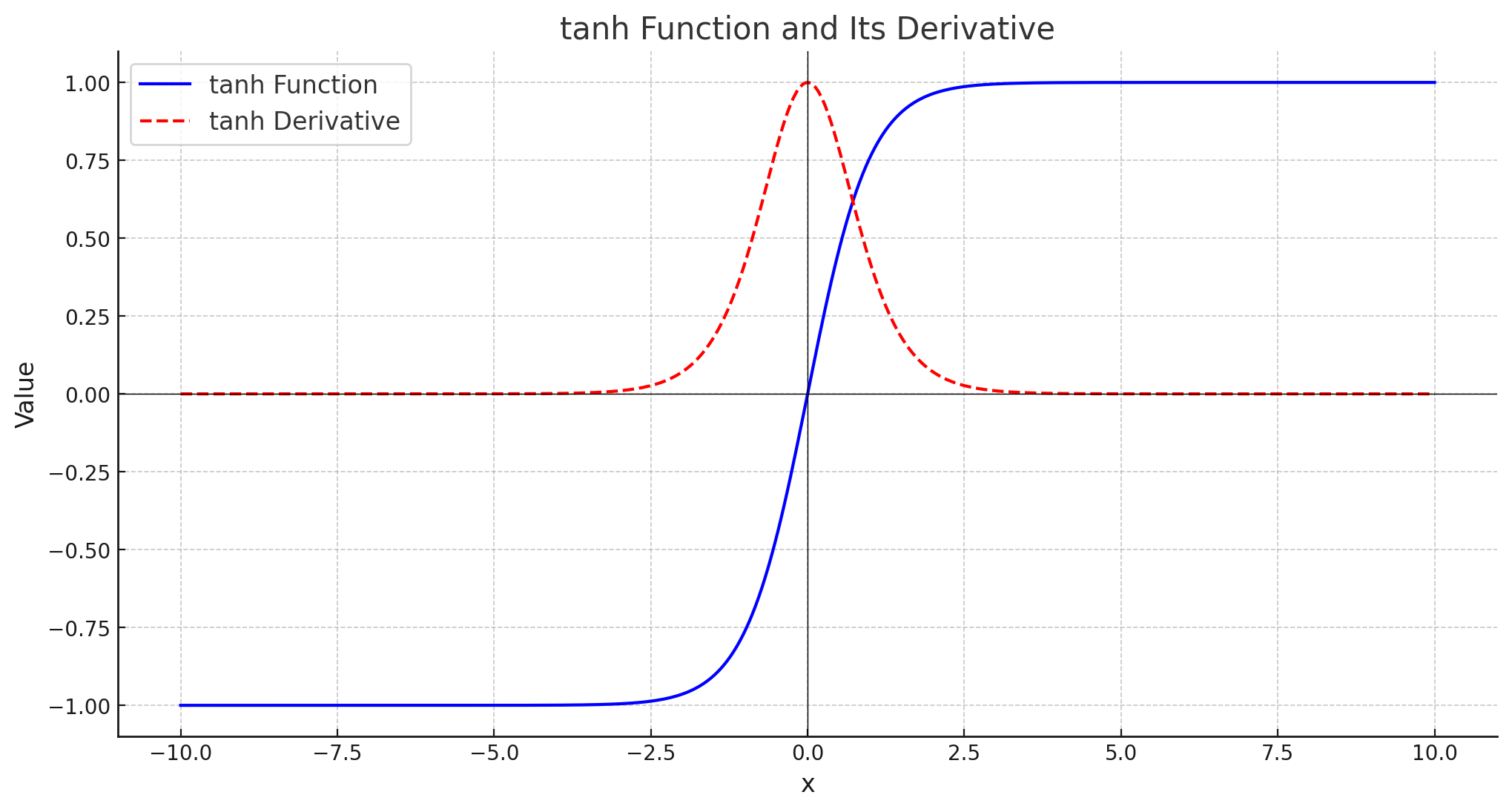
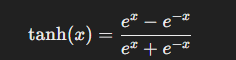
여기 그래프에서 파란색 곡선은 tanh 함수를, 빨간색 점선은 tanh 함수의 미분 값을 나타냅니다.
- tanh 함수는 출력 범위가 (-1, 1)입니다. 입력이 큰 양수나 큰 음수일 경우 출력이 각각 1이나 -1에 가까워집니다.
- tanh 함수의 미분 값은 중심부에서 최대치를 가지며, 입력 값이 크거나 작을수록 미분 값이 0에 가까워집니다. 이러한 특성 때문에 깊은 신경망에서 Vanishing Gradient 문제가 발생할 수 있습니다.
tanh는 sigmoid 와 달리 출력 범위가 -1에서 1이기 때문에, 평균이 0에 가까워지는 특성이 있습니다. 이로 인해 sigmoid 에 비해 학습이 더 빠르고 Vanishing Gradient 문제가 조금 완화되지만, 여전히 깊은 네트워크에서는 기울기가 소멸될 가능성이 있습니다.
2. Dead Neuron 문제
- 정의: 특정 뉴런이 학습 도중 영구적으로 출력 값이 0이 되어, 이후에 입력을 받아도 더 이상 활성화되지 않는 문제를 의미합니다. 이를 '죽은 뉴런(dead neuron)'이라고 부릅니다.
- 발생 원인: 주로 ReLU(Rectified Linear Unit) 활성화 함수에서 발생합니다. ReLU는 입력 값이 0보다 작으면 출력이 0이 되는데, 특정 조건 하에서 뉴런이 계속 0으로 출력되면 가중치 업데이트가 이루어지지 않으면서 '죽은' 상태가 되어버립니다.
- 영향: 죽은 뉴런은 학습 과정에서 더 이상 기여하지 않으므로, 모델의 학습 능력을 감소시키고 표현력 또한 제한됩니다.
- 해결 방법:
- Leaky ReLU나 Parametric ReLU 같은 변형된 활성화 함수 사용
- 적절한 학습률 설정 (학습률이 너무 크면 쉽게 죽은 뉴런이 발생)
- 가중치 초기화를 신중하게 설정하여 뉴런이 쉽게 죽지 않도록 함
ReLU 함수의 특징
- ReLU (Rectified Linear Unit) 활성화 함수는 다음과 같이 정의됩니다:
- f(x) = max(0, x)
- 즉, 입력이 양수이면 그대로 출력되고, 음수면 출력이 0이 됩니다.
- 이 때문에, 입력이 음수일 때 해당 뉴런의 출력은 항상 0이 됩니다.
기울기와 미분
- ReLU 함수의 미분은 다음과 같습니다:
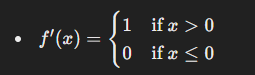
- 입력이 음수이거나 0인 경우 미분 값이 0이기 때문에, 역전파 시 가중치 업데이트가 이루어지지 않습니다.
- 이러한 상황이 계속되면, 뉴런이 항상 0을 출력하게 되면서 '죽은 뉴런(dead neuron)' 상태가 됩니다.
Dead Neuron 문제
- 만약 가중치가 학습 과정에서 특정한 방향으로 업데이트되어 해당 뉴런의 입력이 계속해서 음수가 된다면, 그 뉴런은 역전파 과정에서 기울기가 계속 0이 되고, 학습이 멈춥니다.
- 결국, 해당 뉴런은 더 이상 네트워크의 출력에 기여하지 않게 되며, 이는 dead neuron 문제라고 부릅니다.
- 특히, 학습률이 너무 크거나 가중치 초기화가 적절하지 않을 때 발생할 가능성이 큽니다.
해결책
- Leaky ReLU: Leaky ReLU는 입력이 음수일 때도 작은 기울기를 가지도록 하여 뉴런이 완전히 죽는 것을 방지합니다. 일반적으로 f(x)=max(0.01x, x) 로 정의되며, 음수 영역에서 작은 기울기(예: 0.01)를 갖습니다.
- Parametric ReLU (PReLU): Leaky ReLU와 유사하지만, 음수 영역에서의 기울기를 학습 가능하게 만든 버전입니다. 이는 모델이 최적의 기울기를 스스로 찾도록 도와줍니다.
- Randomized Leaky ReLU (RReLU): Leaky ReLU와 비슷하지만, 음수 구간에서의 기울기를 무작위로 설정합니다. 이는 일반화 성능을 높이기 위한 기법입니다.
- 가중치 초기화 및 적절한 학습률 설정: ReLU 뉴런이 너무 쉽게 죽지 않도록, 가중치 초기화를 잘 설계하고 학습률을 적절히 조정하는 것도 중요합니다.
ReLU 함수와 미분값 시각화
# ReLU 함수 및 그 미분값 정의
def relu(x):
return np.maximum(0, x)
def relu_derivative(x):
return np.where(x > 0, 1, 0)
# ReLU와 그 미분 값 계산
y_relu = relu(x)
y_relu_derivative = relu_derivative(x)
# 그래프 생성
plt.figure(figsize=(12, 6))
# ReLU 함수 그래프
plt.plot(x, y_relu, label='ReLU Function', color='b')
# ReLU 미분 값 그래프
plt.plot(x, y_relu_derivative, label='ReLU Derivative', color='r', linestyle='--')
# 그래프 설정
plt.xlabel('x', fontsize=12)
plt.ylabel('Value', fontsize=12)
plt.title('ReLU Function and Its Derivative', fontsize=15)
plt.axhline(0, color='black', lw=0.5)
plt.axvline(0, color='black', lw=0.5)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 그래프 표시
plt.show()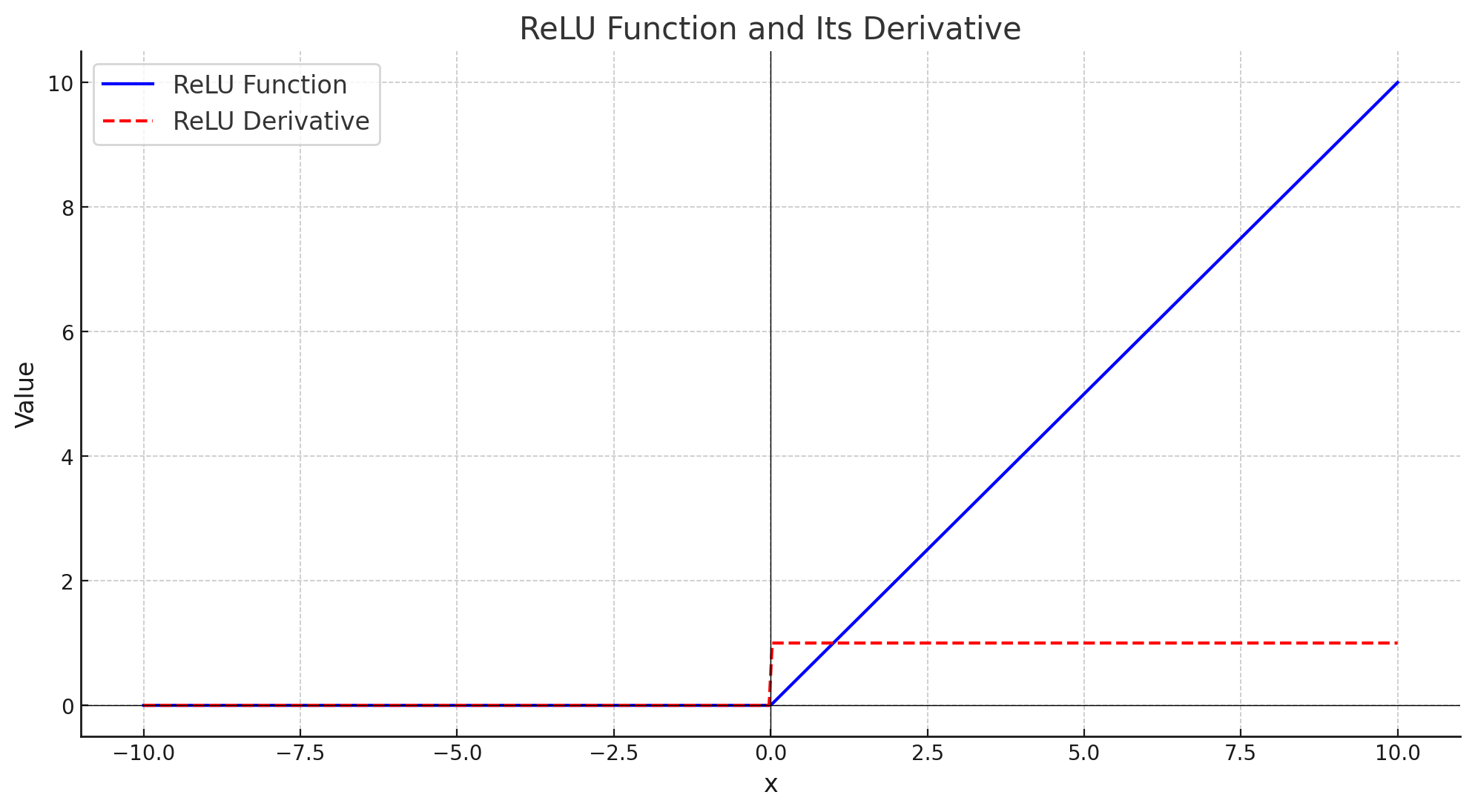
여기 그래프에서 파란색 곡선은 ReLU 함수를, 빨간색 점선은 ReLU 함수의 미분 값을 나타냅니다.
- ReLU 함수는 입력 값이 양수일 때는 그대로 출력하고, 음수일 때는 0을 출력합니다. 이는 신경망에서 활성화를 단순하고 효율적으로 유지하는 역할을 합니다.
- ReLU 함수의 미분 값은 입력이 양수일 때는 1이고, 음수일 때는 0입니다. 이 때문에 ReLU는 양수 영역에서는 기울기를 유지하므로 Vanishing Gradient 문제를 어느 정도 해결할 수 있습니다. 하지만 음수 입력에서는 기울기가 0이 되어 dead neuron 문제가 발생할 수 있습니다.
이와 같은 ReLU의 특성 덕분에 깊은 신경망에서 학습이 잘 이루어지지만, 음수 영역에서 뉴런이 비활성화될 위험이 있음을 알 수 있습니다.
3. 두가지 문제 비교
Dead neuron 문제와 Vanishing gradient 문제 모두 기울기가 0이 되어 학습이 멈추는 공통점이 있기 때문에, 둘 사이에는 어느 정도 유사성이 있습니다. 하지만 그럼에도 불구하고, 이 둘은 발생 원인과 일반적인 발생 상황에서 중요한 차이가 있습니다. 각각의 특성과 차이점을 조금 더 깊이 비교해 보겠습니다.
공통점
- 기울기가 0이 되어 학습이 멈춤: 두 문제 모두 기울기가 0이 되어 역전파를 통해 가중치를 업데이트할 수 없게 되는 상황이 공통적으로 발생합니다.
- 결과적으로, 뉴런의 학습이 중단되어 네트워크의 일부 또는 전체가 제대로 학습하지 못하게 됩니다.
차이점
- 발생 원인
- Vanishing Gradient 문제는 주로 깊은 신경망에서 발생하는 현상으로, 역전파를 거치면서 기울기가 점점 작아지는 현상입니다. 이로 인해 네트워크 초기층의 가중치가 거의 업데이트되지 않게 됩니다. 이러한 현상은 주로 sigmoid나 tanh 같은 포화(activation saturation) 특성을 가진 활성화 함수에서 많이 나타납니다. 이 함수들은 특정 구간에서 출력이 포화되면 그 기울기가 매우 작아지기 때문에, 역전파 중에 그래디언트가 계속 소멸해 나가는 문제가 발생합니다.
- Dead Neuron 문제는 특정 뉴런이 학습 도중에 영구적으로 활성화되지 않는 상황에서 발생합니다. 주로 ReLU 활성화 함수에서 발생하며, 뉴런의 입력이 음수로 고정되면 해당 뉴런은 더 이상 활성화되지 않고 기울기 역시 0이 되어 죽은 상태로 유지됩니다. 이는 주로 가중치 초기화나 학습률 설정에 의해 뉴런이 활성화 영역에 들어가지 못하는 경우에 발생합니다.
- 영향을 받는 층
- Vanishing Gradient 문제는 신경망의 초기층에서 발생하며, 특히 네트워크가 깊어질수록 영향을 많이 받습니다. 깊은 신경망에서 그래디언트가 점점 소멸하면서 초기층의 학습이 제대로 이루어지지 않습니다.
- Dead Neuron 문제는 네트워크의 특정 뉴런에 영향을 미칩니다. 해당 뉴런이 죽으면 네트워크의 다른 부분은 여전히 학습할 수 있지만, 죽은 뉴런은 더 이상 학습에 기여하지 못합니다.
- 발생 환경
- Vanishing Gradient는 주로 깊은 네트워크와 포화형 활성화 함수를 사용했을 때 발생합니다. 예를 들어, Sigmoid는 출력 값이 0 또는 1에 가까울 때 기울기가 매우 작아지는 특성 때문에 기울기 소멸 문제가 자주 발생합니다.
- Dead Neuron은 ReLU 활성화 함수에서 발생하는 특유의 문제입니다. 음수 입력이 들어오면 기울기가 0이 되고, 이 상태가 지속되면 해당 뉴런은 학습 중에 '죽어' 버립니다.
정리하자면
- Vanishing Gradient 문제와 Dead Neuron 문제는 모두 기울기(gradient)가 0이 되어 학습이 멈추는 공통점을 가지고 있습니다.
- 하지만, Vanishing Gradient는 주로 깊은 네트워크에서 발생하며 기울기가 소멸하는 문제인 반면, Dead Neuron은 특정 뉴런이 ReLU 활성화 함수의 특성 때문에 활성화되지 않고 죽는 문제입니다.
- Vanishing gradient 는 네트워크의 전체적 학습에 영향을 주며, Dead neuron 은 개별 뉴런에 영향을 주기 때문에 그 영향력의 범위와 심각성에서도 차이가 있습니다.
'AI' 카테고리의 다른 글
| TensorFlow 함수형 API 로 AlexNet 논문 구현 (1) | 2024.11.18 |
|---|---|
| Colab 에서 Kaggle 데이터 API 로 받기 (3) | 2024.11.15 |
| ViT 에서 언급한 CNN 의 Inductive bias 에 대해 알아보자 (3) | 2024.11.13 |
| .ipynb_checkpoints 을 git 버전 관리에서 제거하기 (0) | 2024.11.12 |
| 분류 모델의 평가 지표 (1) | 2024.10.29 |



